Create a Japanese version of the README.md file named ReadmeJP.md. This makes the project more accessible to Japanese-speaking users.
14 KiB
WhisperLiveKit
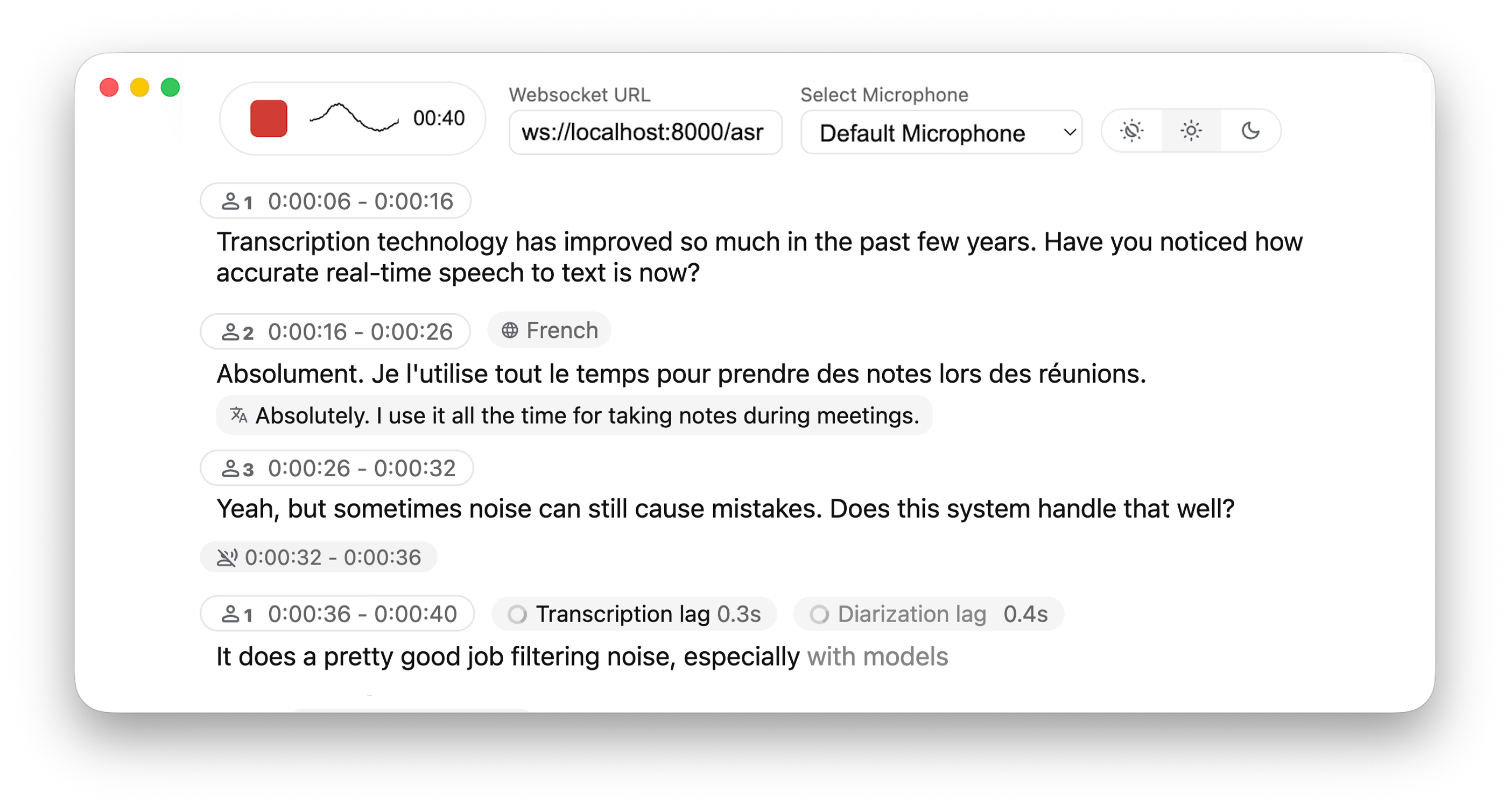
話者識別機能付き、リアルタイム、完全ローカルな音声テキスト変換

すぐに使えるバックエンド+サーバーとシンプルなフロントエンドで、リアルタイムの音声文字起こしをブラウザに直接提供します。✨
主要な研究による技術:
- SimulStreaming (SOTA 2025) - AlignAttポリシーによる超低遅延文字起こし
- WhisperStreaming (SOTA 2023) - LocalAgreementポリシーによる低遅延文字起こし
- Streaming Sortformer (SOTA 2025) - 高度なリアルタイム話者ダイアライゼーション
- Diart (SOTA 2021) - リアルタイム話者ダイアライゼーション
- Silero VAD (2024) - エンタープライズグレードの音声区間検出
なぜ各音声バッチで単純なWhisperモデルを実行しないのか? Whisperは完全な発話向けに設計されており、リアルタイムのチャンク向けではありません。小さなセグメントを処理するとコンテキストが失われ、単語が音節の途中で途切れ、質の悪い文字起こしになります。WhisperLiveKitは、インテリジェントなバッファリングとインクリメンタルな処理のために、最先端の同時音声研究を利用しています。
アーキテクチャ
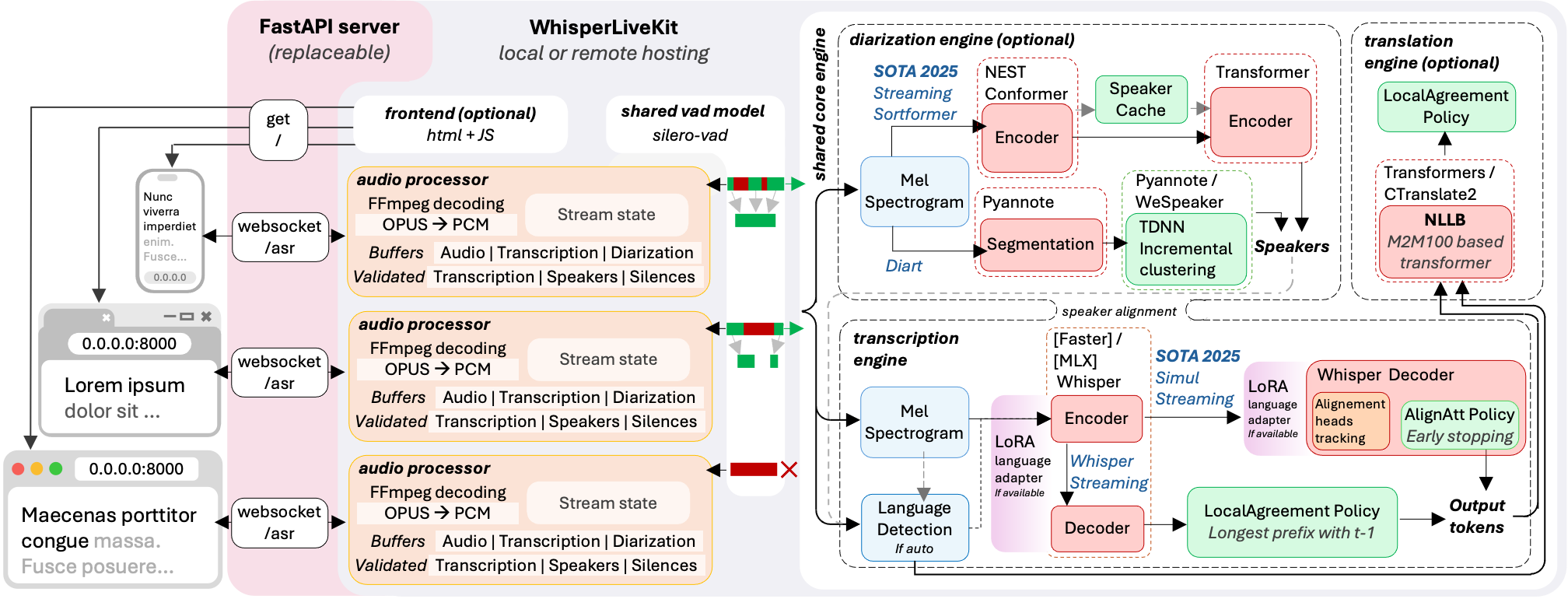
バックエンドは複数の同時ユーザーをサポートします。音声が検出されない場合、音声区間検出がオーバーヘッドを削減します。
インストールとクイックスタート
pip install whisperlivekit
FFmpegが必要です WhisperLiveKitを使用する前にインストールする必要があります。
OS インストール方法 Ubuntu/Debian sudo apt install ffmpegMacOS brew install ffmpegWindows https://ffmpeg.org/download.html から.exeをダウンロードし、PATHに追加
クイックスタート
-
文字起こしサーバーを起動します:
whisperlivekit-server --model base --language en -
ブラウザを開き
http://localhost:8000にアクセスします。話し始めると、あなたの言葉がリアルタイムで表示されます!
- 利用可能なすべての言語のリストについては、tokenizer.py を参照してください。
- HTTPSの要件については、パラメータセクションのSSL設定オプションを参照してください。
オプションの依存関係
| オプション | pip install |
|---|---|
| Sortformerによる話者ダイアライゼーション | git+https://github.com/NVIDIA/NeMo.git@main#egg=nemo_toolkit[asr] |
| Diartによる話者ダイアライゼーション | diart |
| オリジナルのWhisperバックエンド | whisper |
| タイムスタンプ改善バックエンド | whisper-timestamped |
| Apple Silicon最適化バックエンド | mlx-whisper |
| OpenAI APIバックエンド | openai |
それらの使用方法については、以下のパラメータと設定を参照してください。
使用例
コマンドラインインターフェース: 様々なオプションで文字起こしサーバーを起動します:
# デフォルト(small)より良いモデルを使用
whisperlivekit-server --model large-v3
# ダイアライゼーションと言語を指定した高度な設定
whisperlivekit-server --host 0.0.0.0 --port 8000 --model medium --diarization --language fr
Python API連携: 関数やクラスの使用方法のより完全な例については、basic_server を確認してください。
from whisperlivekit import TranscriptionEngine, AudioProcessor, parse_args
from fastapi import FastAPI, WebSocket, WebSocketDisconnect
from fastapi.responses import HTMLResponse
from contextlib import asynccontextmanager
import asyncio
transcription_engine = None
@asynccontextmanager
async def lifespan(app: FastAPI):
global transcription_engine
transcription_engine = TranscriptionEngine(model="medium", diarization=True, lan="en")
yield
app = FastAPI(lifespan=lifespan)
async def handle_websocket_results(websocket: WebSocket, results_generator):
async for response in results_generator:
await websocket.send_json(response)
await websocket.send_json({"type": "ready_to_stop"})
@app.websocket("/asr")
async def websocket_endpoint(websocket: WebSocket):
global transcription_engine
# 接続ごとに新しいAudioProcessorを作成し、共有エンジンを渡す
audio_processor = AudioProcessor(transcription_engine=transcription_engine)
results_generator = await audio_processor.create_tasks()
results_task = asyncio.create_task(handle_websocket_results(websocket, results_generator))
await websocket.accept()
while True:
message = await websocket.receive_bytes()
await audio_processor.process_audio(message)
フロントエンド実装: パッケージにはHTML/JavaScript実装がここに含まれています。from whisperlivekit import get_web_interface_html & page = get_web_interface_html() を使ってインポートすることもできます。
パラメータと設定
重要なパラメータのリストを変更できます。しかし、何を変更すべきでしょうか?
--modelサイズ。リストと推奨事項はこちら--language。リストはこちら。autoを使用すると、モデルは自動的に言語を検出しようとしますが、英語に偏る傾向があります。--backend?simulstreamingが正しく動作しない場合や、デュアルライセンス要件を避けたい場合は--backend faster-whisperに切り替えることができます。--warmup-file、もしあれば--host,--port,--ssl-certfile,--ssl-keyfile、サーバーをセットアップする場合--diarization、使用したい場合。
残りは推奨しません。しかし、以下があなたのオプションです。
| パラメータ | 説明 | デフォルト |
|---|---|---|
--model |
Whisperモデルのサイズ。 | small |
--language |
ソース言語コードまたはauto |
auto |
--task |
transcribeまたはtranslate |
transcribe |
--backend |
処理バックエンド | simulstreaming |
--min-chunk-size |
最小音声チャンクサイズ(秒) | 1.0 |
--no-vac |
音声アクティビティコントローラーを無効化 | False |
--no-vad |
音声区間検出を無効化 | False |
--warmup-file |
モデルのウォームアップ用音声ファイルパス | jfk.wav |
--host |
サーバーホストアドレス | localhost |
--port |
サーバーポート | 8000 |
--ssl-certfile |
SSL証明書ファイルへのパス(HTTPSサポート用) | None |
--ssl-keyfile |
SSL秘密鍵ファイルへのパス(HTTPSサポート用) | None |
| WhisperStreamingバックエンドオプション | 説明 | デフォルト |
|---|---|---|
--confidence-validation |
高速な検証のために信頼スコアを使用 | False |
--buffer_trimming |
バッファトリミング戦略(sentenceまたはsegment) |
segment |
| SimulStreamingバックエンドオプション | 説明 | デフォルト |
|---|---|---|
--frame-threshold |
AlignAttフレームしきい値(低いほど速く、高いほど正確) | 25 |
--beams |
ビームサーチのビーム数(1 = 貪欲デコーディング) | 1 |
--decoder |
デコーダタイプを強制(beamまたはgreedy) |
auto |
--audio-max-len |
最大音声バッファ長(秒) | 30.0 |
--audio-min-len |
処理する最小音声長(秒) | 0.0 |
--cif-ckpt-path |
単語境界検出用CIFモデルへのパス | None |
--never-fire |
未完了の単語を決して切り捨てない | False |
--init-prompt |
モデルの初期プロンプト | None |
--static-init-prompt |
スクロールしない静的プロンプト | None |
--max-context-tokens |
最大コンテキストトークン数 | None |
--model-path |
.ptモデルファイルへの直接パス。見つからない場合はダウンロード | ./base.pt |
--preloaded-model-count |
オプション。メモリにプリロードするモデルの数(予想される同時ユーザー数まで設定) | 1 |
| ダイアライゼーションオプション | 説明 | デフォルト |
|---|---|---|
--diarization |
話者識別を有効化 | False |
--diarization-backend |
diartまたはsortformer |
sortformer |
--segmentation-model |
DiartセグメンテーションモデルのHugging FaceモデルID。利用可能なモデル | pyannote/segmentation-3.0 |
--embedding-model |
Diart埋め込みモデルのHugging FaceモデルID。利用可能なモデル | speechbrain/spkrec-ecapa-voxceleb |
Diartを使用したダイアライゼーションには、pyannote.audioモデルへのアクセスが必要です:
🚀 デプロイガイド
WhisperLiveKitを本番環境にデプロイするには:
-
サーバーセットアップ: 本番用ASGIサーバーをインストールし、複数のワーカーで起動します
pip install uvicorn gunicorn gunicorn -k uvicorn.workers.UvicornWorker -w 4 your_app:app -
フロントエンド: カスタマイズした
htmlのバージョンをホストし、WebSocket接続が正しくポイントするようにします -
Nginx設定 (本番環境で推奨):
server { listen 80; server_name your-domain.com; location / { proxy_pass http://localhost:8000; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; proxy_set_header Host $host; }} -
HTTPSサポート: 安全なデプロイメントのために、WebSocket URLで "ws://" の代わりに "wss://" を使用します
🐋 Docker
GPUまたはCPUサポート付きでDockerを使用してアプリケーションを簡単にデプロイします。
前提条件
- Dockerがシステムにインストールされていること
- GPUサポートの場合: NVIDIA Dockerランタイムがインストールされていること
クイックスタート
GPUアクセラレーション付き (推奨):
docker build -t wlk .
docker run --gpus all -p 8000:8000 --name wlk wlk
CPUのみ:
docker build -f Dockerfile.cpu -t wlk .
docker run -p 8000:8000 --name wlk wlk
高度な使用法
カスタム設定:
# カスタムモデルと言語の例
docker run --gpus all -p 8000:8000 --name wlk wlk --model large-v3 --language fr
メモリ要件
- 大規模モデル: Dockerランタイムに十分なメモリが割り当てられていることを確認してください
カスタマイズ
--build-argオプション:EXTRAS="whisper-timestamped"- イメージのインストールにエクストラを追加します(スペースなし)。必要なコンテナオプションを設定することを忘れないでください!HF_PRECACHE_DIR="./.cache/"- 初回起動を高速化するためにモデルキャッシュをプリロードしますHF_TKN_FILE="./token"- ゲート付きモデルをダウンロードするためにHugging Face Hubアクセストークンを追加します
🔮 ユースケース
会議の文字起こしのためにリアルタイムで議論をキャプチャする、聴覚障害のあるユーザーがアクセシビリティツールを通じて会話を追うのを助ける、コンテンツ作成のためにポッドキャストやビデオを自動的に文字起こしする、カスタマーサービスのために話者識別付きでサポートコールを文字起こしする...