 @@ -14,7 +14,7 @@
@@ -14,7 +14,7 @@
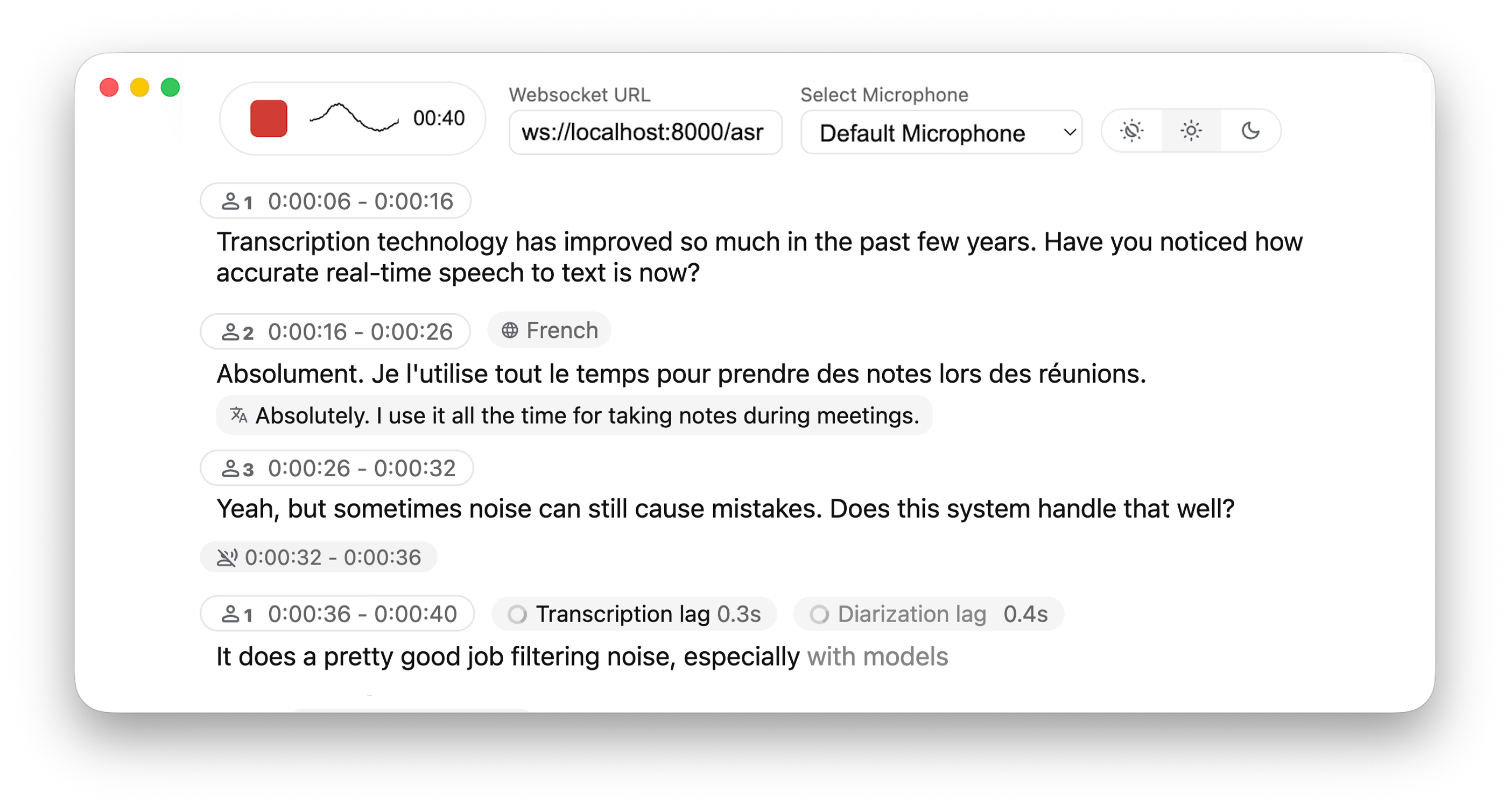 -
-Real-time, Fully Local Speech-to-Text with Speaker Diarization
+Real-time, Fully Local Speech-to-Text with Speaker Identification
 +
+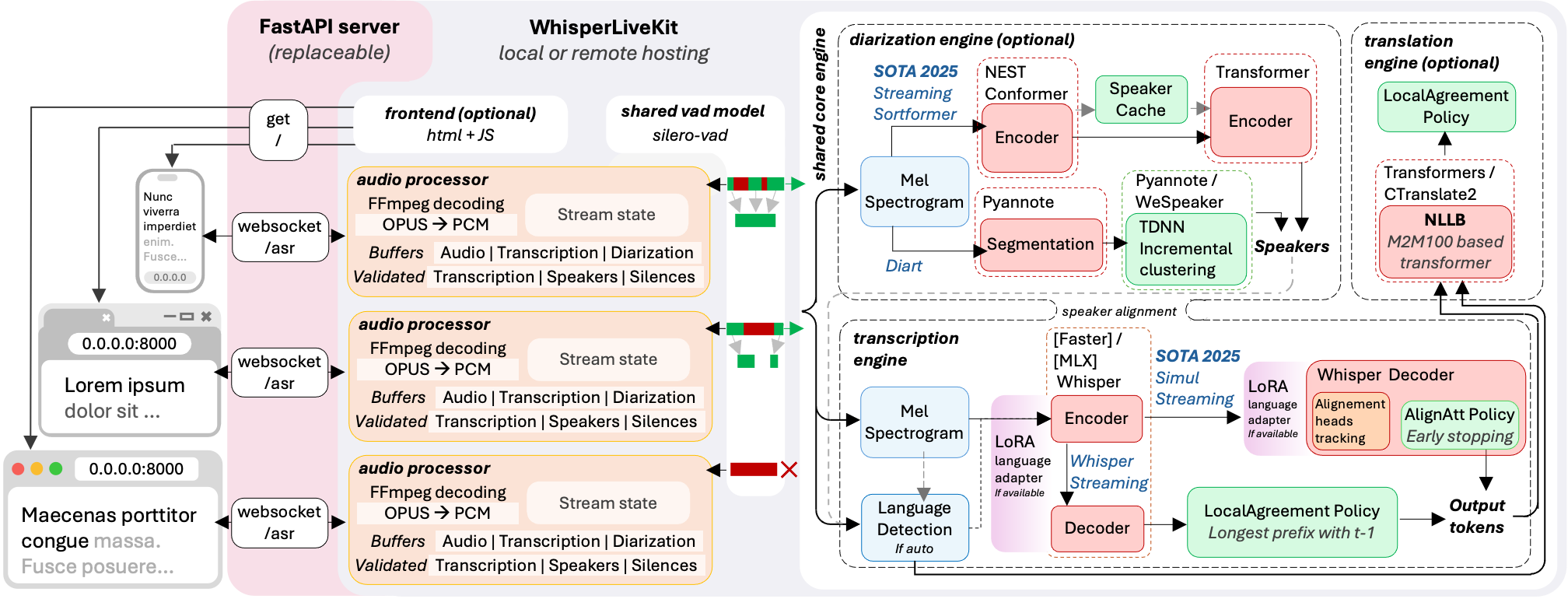 +
+*The backend supports multiple concurrent users. Voice Activity Detection reduces overhead when no voice is detected.*
### Installation & Quick Start
@@ -57,14 +51,16 @@ pip install whisperlivekit
#### Quick Start
1. **Start the transcription server:**
```bash
- whisperlivekit-server --model tiny.en
+ whisperlivekit-server --model base --language en
```
-2. **Open your browser** and navigate to `http://localhost:8000`
+2. **Open your browser** and navigate to `http://localhost:8000`. Start speaking and watch your words appear in real-time!
-3. **Start speaking** and watch your words appear in real-time!
-> For HTTPS requirements, see the **Parameters** section for SSL configuration options.
+> - See [tokenizer.py](https://github.com/QuentinFuxa/WhisperLiveKit/blob/main/whisperlivekit/simul_whisper/whisper/tokenizer.py) for the list of all available languages.
+> - For HTTPS requirements, see the **Parameters** section for SSL configuration options.
+
+
#### Optional Dependencies
@@ -151,18 +147,18 @@ The package includes an HTML/JavaScript implementation [here](https://github.com
| Parameter | Description | Default |
|-----------|-------------|---------|
-| `--host` | Server host address | `localhost` |
-| `--port` | Server port | `8000` |
-| `--ssl-certfile` | Path to the SSL certificate file (for HTTPS support) | `None` |
-| `--ssl-keyfile` | Path to the SSL private key file (for HTTPS support) | `None` |
-| `--model` | Whisper model size. | `tiny` |
+| `--model` | Whisper model size. | `small` |
| `--language` | Source language code or `auto` | `en` |
| `--task` | `transcribe` or `translate` | `transcribe` |
-| `--backend` | Processing backend | `faster-whisper` |
+| `--backend` | Processing backend | `simulstreaming` |
| `--min-chunk-size` | Minimum audio chunk size (seconds) | `1.0` |
| `--no-vac` | Disable Voice Activity Controller | `False` |
| `--no-vad` | Disable Voice Activity Detection | `False` |
| `--warmup-file` | Audio file path for model warmup | `jfk.wav` |
+| `--host` | Server host address | `localhost` |
+| `--port` | Server port | `8000` |
+| `--ssl-certfile` | Path to the SSL certificate file (for HTTPS support) | `None` |
+| `--ssl-keyfile` | Path to the SSL private key file (for HTTPS support) | `None` |
| WhisperStreaming backend options | Description | Default |
diff --git a/whisperlivekit/audio_processor.py b/whisperlivekit/audio_processor.py
index 552c3af..8e23ef2 100644
--- a/whisperlivekit/audio_processor.py
+++ b/whisperlivekit/audio_processor.py
@@ -301,7 +301,7 @@ class AudioProcessor:
transcription_lag_s = max(0.0, time() - self.beg_loop - self.end_buffer)
asr_processing_logs = f"internal_buffer={asr_internal_buffer_duration_s:.2f}s | lag={transcription_lag_s:.2f}s |"
if type(item) is Silence:
- asr_processing_logs += f" + Silence of = {item.duration :.2fs} | last_end = {self.tokens[-1].end} |"
+ asr_processing_logs += f" + Silence of = {item.duration:.2f}s | last_end = {self.tokens[-1].end} |"
logger.info(asr_processing_logs)
if type(item) is Silence:
diff --git a/whisperlivekit/parse_args.py b/whisperlivekit/parse_args.py
index 9e54698..2243f4d 100644
--- a/whisperlivekit/parse_args.py
+++ b/whisperlivekit/parse_args.py
@@ -82,7 +82,7 @@ def parse_args():
parser.add_argument(
"--model",
type=str,
- default="tiny",
+ default="small",
help="Name size of the Whisper model to use (default: tiny). Suggested values: tiny.en,tiny,base.en,base,small.en,small,medium.en,medium,large-v1,large-v2,large-v3,large,large-v3-turbo. The model is automatically downloaded from the model hub if not present in model cache dir.",
)
@@ -115,7 +115,7 @@ def parse_args():
parser.add_argument(
"--backend",
type=str,
- default="faster-whisper",
+ default="simulstreaming",
choices=["faster-whisper", "whisper_timestamped", "mlx-whisper", "openai-api", "simulstreaming"],
help="Load only this backend for Whisper processing.",
)
+
+*The backend supports multiple concurrent users. Voice Activity Detection reduces overhead when no voice is detected.*
### Installation & Quick Start
@@ -57,14 +51,16 @@ pip install whisperlivekit
#### Quick Start
1. **Start the transcription server:**
```bash
- whisperlivekit-server --model tiny.en
+ whisperlivekit-server --model base --language en
```
-2. **Open your browser** and navigate to `http://localhost:8000`
+2. **Open your browser** and navigate to `http://localhost:8000`. Start speaking and watch your words appear in real-time!
-3. **Start speaking** and watch your words appear in real-time!
-> For HTTPS requirements, see the **Parameters** section for SSL configuration options.
+> - See [tokenizer.py](https://github.com/QuentinFuxa/WhisperLiveKit/blob/main/whisperlivekit/simul_whisper/whisper/tokenizer.py) for the list of all available languages.
+> - For HTTPS requirements, see the **Parameters** section for SSL configuration options.
+
+
#### Optional Dependencies
@@ -151,18 +147,18 @@ The package includes an HTML/JavaScript implementation [here](https://github.com
| Parameter | Description | Default |
|-----------|-------------|---------|
-| `--host` | Server host address | `localhost` |
-| `--port` | Server port | `8000` |
-| `--ssl-certfile` | Path to the SSL certificate file (for HTTPS support) | `None` |
-| `--ssl-keyfile` | Path to the SSL private key file (for HTTPS support) | `None` |
-| `--model` | Whisper model size. | `tiny` |
+| `--model` | Whisper model size. | `small` |
| `--language` | Source language code or `auto` | `en` |
| `--task` | `transcribe` or `translate` | `transcribe` |
-| `--backend` | Processing backend | `faster-whisper` |
+| `--backend` | Processing backend | `simulstreaming` |
| `--min-chunk-size` | Minimum audio chunk size (seconds) | `1.0` |
| `--no-vac` | Disable Voice Activity Controller | `False` |
| `--no-vad` | Disable Voice Activity Detection | `False` |
| `--warmup-file` | Audio file path for model warmup | `jfk.wav` |
+| `--host` | Server host address | `localhost` |
+| `--port` | Server port | `8000` |
+| `--ssl-certfile` | Path to the SSL certificate file (for HTTPS support) | `None` |
+| `--ssl-keyfile` | Path to the SSL private key file (for HTTPS support) | `None` |
| WhisperStreaming backend options | Description | Default |
diff --git a/whisperlivekit/audio_processor.py b/whisperlivekit/audio_processor.py
index 552c3af..8e23ef2 100644
--- a/whisperlivekit/audio_processor.py
+++ b/whisperlivekit/audio_processor.py
@@ -301,7 +301,7 @@ class AudioProcessor:
transcription_lag_s = max(0.0, time() - self.beg_loop - self.end_buffer)
asr_processing_logs = f"internal_buffer={asr_internal_buffer_duration_s:.2f}s | lag={transcription_lag_s:.2f}s |"
if type(item) is Silence:
- asr_processing_logs += f" + Silence of = {item.duration :.2fs} | last_end = {self.tokens[-1].end} |"
+ asr_processing_logs += f" + Silence of = {item.duration:.2f}s | last_end = {self.tokens[-1].end} |"
logger.info(asr_processing_logs)
if type(item) is Silence:
diff --git a/whisperlivekit/parse_args.py b/whisperlivekit/parse_args.py
index 9e54698..2243f4d 100644
--- a/whisperlivekit/parse_args.py
+++ b/whisperlivekit/parse_args.py
@@ -82,7 +82,7 @@ def parse_args():
parser.add_argument(
"--model",
type=str,
- default="tiny",
+ default="small",
help="Name size of the Whisper model to use (default: tiny). Suggested values: tiny.en,tiny,base.en,base,small.en,small,medium.en,medium,large-v1,large-v2,large-v3,large,large-v3-turbo. The model is automatically downloaded from the model hub if not present in model cache dir.",
)
@@ -115,7 +115,7 @@ def parse_args():
parser.add_argument(
"--backend",
type=str,
- default="faster-whisper",
+ default="simulstreaming",
choices=["faster-whisper", "whisper_timestamped", "mlx-whisper", "openai-api", "simulstreaming"],
help="Load only this backend for Whisper processing.",
)