From ff8fd0ec7216a63a2ca5a1fd348a41df06740c64 Mon Sep 17 00:00:00 2001
From: Quentin Fuxa <38427957+QuentinFuxa@users.noreply.github.com>
Date: Fri, 28 Mar 2025 14:30:14 +0100
Subject: [PATCH 1/2] Update README.md
---
README.md | 286 +++++++++++++++++++++++++++++++++++++-----------------
1 file changed, 195 insertions(+), 91 deletions(-)
diff --git a/README.md b/README.md
index 78b5d65..ab67f19 100644
--- a/README.md
+++ b/README.md
@@ -1,43 +1,69 @@
WhisperLiveKit
-Real-time, Fully Local Whisper's Speech-to-Text and Speaker Diarization
- -
- -
- +
+ 
-This project is based on [Whisper Streaming](https://github.com/ufal/whisper_streaming) and lets you transcribe audio directly from your browser. Simply launch the local server and grant microphone access. Everything runs locally on your machine ✨
+Real-time, Fully Local Speech-to-Text with Speaker Diarization
-
+
+  +
+
+
+ 
-### Differences from [Whisper Streaming](https://github.com/ufal/whisper_streaming)
+## 🚀 Overview
-#### ⚙️ **Core Improvements**
+This project is based on [Whisper Streaming](https://github.com/ufal/whisper_streaming) and lets you transcribe audio directly from your browser. WhisperLiveKit provides a complete backend solution for real-time speech transcription with an example frontend that you can customize for your own needs. Everything runs locally on your machine ✨
+
+### 🔄 Architecture
+
+WhisperLiveKit consists of two main components:
+
+- **Backend (Server)**: FastAPI WebSocket server that processes audio and provides real-time transcription
+- **Frontend Example**: Basic HTML & JavaScript implementation that demonstrates how to capture and stream audio
+
+> **Note**: We recommend installing this library on the server/backend. For the frontend, you can use and adapt the provided HTML template from [whisperlivekit/web/live_transcription.html](https://github.com/QuentinFuxa/WhisperLiveKit/blob/main/whisperlivekit/web/live_transcription.html) for your specific use case.
+
+### ✨ Key Features
+
+- **🎙️ Real-time Transcription** - Convert speech to text instantly as you speak
+- **👥 Speaker Diarization** - Identify different speakers in real-time using [Diart](https://github.com/juanmc2005/diart)
+- **🔒 Fully Local** - All processing happens on your machine - no data sent to external servers
+- **📱 Multi-User Support** - Handle multiple users simultaneously with a single backend/server
+
+### ⚙️ Differences from [Whisper Streaming](https://github.com/ufal/whisper_streaming)
+
+- **Multi-User Support** – Handles multiple users simultaneously by decoupling backend and online ASR
+- **MLX Whisper Backend** – Optimized for Apple Silicon for faster local processing
- **Buffering Preview** – Displays unvalidated transcription segments
-- **Multi-User Support** – Handles multiple users simultaneously by decoupling backend and online asr
-- **MLX Whisper Backend** – Optimized for Apple Silicon for faster local processing.
-- **Confidence validation** – Immediately validate high-confidence tokens for faster inference
+- **Confidence Validation** – Immediately validate high-confidence tokens for faster inference
+- **Apple Silicon Optimized** - MLX backend for faster local processing on Mac
-#### 🎙️ **Speaker Identification**
-- **Real-Time Diarization** – Identify different speakers in real time using [Diart](https://github.com/juanmc2005/diart)
+## 📖 Quick Start
-#### 🌐 **Web & API**
-- **Built-in Web UI** – Simple raw html browser interface with no frontend setup required
-- **FastAPI WebSocket Server** – Real-time speech-to-text processing with async FFmpeg streaming.
-- **JavaScript Client** – Ready-to-use MediaRecorder implementation for seamless client-side integration.
+```bash
+# Install the package
+pip install whisperlivekit
-## Installation
+# Start the transcription server
+whisperlivekit-server --model tiny.en
-### Via pip (recommended)
+# Open your browser at http://localhost:8000
+```
+
+That's it! Start speaking and watch your words appear on screen.
+
+## 🛠️ Installation Options
+
+### Install from PyPI (Recommended)
```bash
pip install whisperlivekit
```
-### From source
+### Install from Source
```bash
git clone https://github.com/QuentinFuxa/WhisperLiveKit
@@ -47,78 +73,86 @@ pip install -e .
### System Dependencies
-You need to install FFmpeg on your system:
+FFmpeg is required:
```bash
-# For Ubuntu/Debian:
+# Ubuntu/Debian
sudo apt install ffmpeg
-# For macOS:
+# macOS
brew install ffmpeg
-# For Windows:
+# Windows
# Download from https://ffmpeg.org/download.html and add to PATH
```
### Optional Dependencies
```bash
-# If you want to use VAC (Voice Activity Controller). Useful for preventing hallucinations
+# Voice Activity Controller (prevents hallucinations)
pip install torch
-
-# If you choose sentences as buffer trimming strategy
+
+# Sentence-based buffer trimming
pip install mosestokenizer wtpsplit
pip install tokenize_uk # If you work with Ukrainian text
-# If you want to use diarization
+# Speaker diarization
pip install diart
-# Optional backends. Default is faster-whisper
-pip install whisperlivekit[whisper] # Original Whisper backend
-pip install whisperlivekit[whisper-timestamped] # Whisper with improved timestamps
-pip install whisperlivekit[mlx-whisper] # Optimized for Apple Silicon
-pip install whisperlivekit[openai] # OpenAI API backend
+# Alternative Whisper backends (default is faster-whisper)
+pip install whisperlivekit[whisper] # Original Whisper
+pip install whisperlivekit[whisper-timestamped] # Improved timestamps
+pip install whisperlivekit[mlx-whisper] # Apple Silicon optimization
+pip install whisperlivekit[openai] # OpenAI API
```
-### Get access to 🎹 pyannote models
+### 🎹 Pyannote Models Setup
-By default, diart is based on [pyannote.audio](https://github.com/pyannote/pyannote-audio) models from the [huggingface](https://huggingface.co/) hub.
-In order to use them, please follow these steps:
+For diarization, you need access to pyannote.audio models:
-1) [Accept user conditions](https://huggingface.co/pyannote/segmentation) for the `pyannote/segmentation` model
-2) [Accept user conditions](https://huggingface.co/pyannote/segmentation-3.0) for the newest `pyannote/segmentation-3.0` model
-3) [Accept user conditions](https://huggingface.co/pyannote/embedding) for the `pyannote/embedding` model
-4) Install [huggingface-cli](https://huggingface.co/docs/huggingface_hub/quick-start#install-the-hub-library) and [log in](https://huggingface.co/docs/huggingface_hub/quick-start#login) with your user access token (or provide it manually in diart CLI or API).
+1. [Accept user conditions](https://huggingface.co/pyannote/segmentation) for the `pyannote/segmentation` model
+2. [Accept user conditions](https://huggingface.co/pyannote/segmentation-3.0) for the `pyannote/segmentation-3.0` model
+3. [Accept user conditions](https://huggingface.co/pyannote/embedding) for the `pyannote/embedding` model
+4. Login with HuggingFace:
+ ```bash
+ pip install huggingface_hub
+ huggingface-cli login
+ ```
+## 💻 Usage Examples
+### Command-line Interface
-## Usage
-
-### Using the command-line tool
-
-After installation, you can start the server using the provided command-line tool:
+Start the transcription server with various options:
```bash
-whisperlivekit-server --host 0.0.0.0 --port 8000 --model tiny.en
+# Basic server with English model
+whisperlivekit-server --model tiny.en
+
+# Advanced configuration with diarization
+whisperlivekit-server --host 0.0.0.0 --port 8000 --model medium --diarization --language auto
```
-Then open your browser at `http://localhost:8000` (or your specified host and port).
-
-### Using the library in your code
+### Python API Integration (Backend)
```python
from whisperlivekit import WhisperLiveKit
from whisperlivekit.audio_processor import AudioProcessor
from fastapi import FastAPI, WebSocket
+import asyncio
+from fastapi.responses import HTMLResponse
+# Initialize components
+app = FastAPI()
kit = WhisperLiveKit(model="medium", diarization=True)
-app = FastAPI() # Create a FastAPI application
+# Serve the web interface
@app.get("/")
async def get():
- return HTMLResponse(kit.web_interface()) # Use the built-in web interface
+ return HTMLResponse(kit.web_interface()) # Use the built-in web interface
-async def handle_websocket_results(websocket, results_generator): # Sends results to frontend
+# Process WebSocket connections
+async def handle_websocket_results(websocket, results_generator):
async for response in results_generator:
await websocket.send_json(response)
@@ -127,57 +161,127 @@ async def websocket_endpoint(websocket: WebSocket):
audio_processor = AudioProcessor()
await websocket.accept()
results_generator = await audio_processor.create_tasks()
- websocket_task = asyncio.create_task(handle_websocket_results(websocket, results_generator))
+ websocket_task = asyncio.create_task(
+ handle_websocket_results(websocket, results_generator)
+ )
- while True:
- message = await websocket.receive_bytes()
- await audio_processor.process_audio(message)
+ try:
+ while True:
+ message = await websocket.receive_bytes()
+ await audio_processor.process_audio(message)
+ except Exception as e:
+ print(f"WebSocket error: {e}")
+ websocket_task.cancel()
```
-For a complete audio processing example, check [whisper_fastapi_online_server.py](https://github.com/QuentinFuxa/WhisperLiveKit/blob/main/whisper_fastapi_online_server.py)
+### Frontend Implementation
+The package includes a simple HTML/JavaScript implementation that you can adapt for your project. You can get in in [whisperlivekit/web/live_transcription.html](https://github.com/QuentinFuxa/WhisperLiveKit/blob/main/whisperlivekit/web/live_transcription.html), or using :
-## Configuration Options
+```python
+kit.web_interface()
+```
-The following parameters are supported when initializing `WhisperLiveKit`:
+## ⚙️ Configuration Reference
- - `--host` and `--port` let you specify the server's IP/port.
- - `--min-chunk-size` sets the minimum chunk size for audio processing. Make sure this value aligns with the chunk size selected in the frontend. If not aligned, the system will work but may unnecessarily over-process audio data.
- - `--no-transcription`: Disable transcription (enabled by default)
- - `--diarization`: Enable speaker diarization (disabled by default)
- - `--confidence-validation`: Use confidence scores for faster validation. Transcription will be faster but punctuation might be less accurate (disabled by default)
- - `--warmup-file`: The path to a speech audio wav file to warm up Whisper so that the very first chunk processing is fast:
- - If not set, uses https://github.com/ggerganov/whisper.cpp/raw/master/samples/jfk.wav.
- - If False, no warmup is performed.
- - `--min-chunk-size` Minimum audio chunk size in seconds. It waits up to this time to do processing. If the processing takes shorter time, it waits, otherwise it processes the whole segment that was received by this time.
- - `--model`: Name size of the Whisper model to use (default: tiny). Suggested values: tiny.en, tiny, base.en, base, small.en, small, medium.en, medium, large-v1, large-v2, large-v3, large, large-v3-turbo. The model is automatically downloaded from the model hub if not present in model cache dir.
- - `--model_cache_dir`: Overriding the default model cache dir where models downloaded from the hub are saved
- - `--model_dir`: Dir where Whisper model.bin and other files are saved. This option overrides --model and --model_cache_dir parameter.
- - `--lan`, `--language`: Source language code, e.g. en,de,cs, or 'auto' for language detection.
- - `--task` {_transcribe, translate_}: Transcribe or translate. If translate is set, we recommend avoiding the _large-v3-turbo_ backend, as it [performs significantly worse](https://github.com/QuentinFuxa/whisper_streaming_web/issues/40#issuecomment-2652816533) than other models for translation.
- - `--backend` {_faster-whisper, whisper_timestamped, openai-api, mlx-whisper_}: Load only this backend for Whisper processing.
- - `--vac`: Use VAC = voice activity controller. Requires torch. (disabled by default)
- - `--vac-chunk-size`: VAC sample size in seconds.
- - `--no-vad`: Disable VAD (voice activity detection), which is enabled by default.
- - `--buffer_trimming` {_sentence, segment_}: Buffer trimming strategy -- trim completed sentences marked with punctuation mark and detected by sentence segmenter, or the completed segments returned by Whisper. Sentence segmenter must be installed for "sentence" option.
- - `--buffer_trimming_sec`: Buffer trimming length threshold in seconds. If buffer length is longer, trimming sentence/segment is triggered.
+WhisperLiveKit offers extensive configuration options:
+| Parameter | Description | Default |
+|-----------|-------------|---------|
+| `--host` | Server host address | `localhost` |
+| `--port` | Server port | `8000` |
+| `--model` | Whisper model size | `tiny` |
+| `--language` | Source language code or `auto` | `en` |
+| `--task` | `transcribe` or `translate` | `transcribe` |
+| `--backend` | Processing backend | `faster-whisper` |
+| `--diarization` | Enable speaker identification | `False` |
+| `--confidence-validation` | Use confidence scores for faster validation | `False` |
+| `--min-chunk-size` | Minimum audio chunk size (seconds) | `1.0` |
+| `--vac` | Use Voice Activity Controller | `False` |
+| `--no-vad` | Disable Voice Activity Detection | `False` |
+| `--buffer_trimming` | Buffer trimming strategy (`sentence` or `segment`) | `segment` |
+| `--warmup-file` | Audio file path for model warmup | `jfk.wav` |
-## How the Live Interface Works
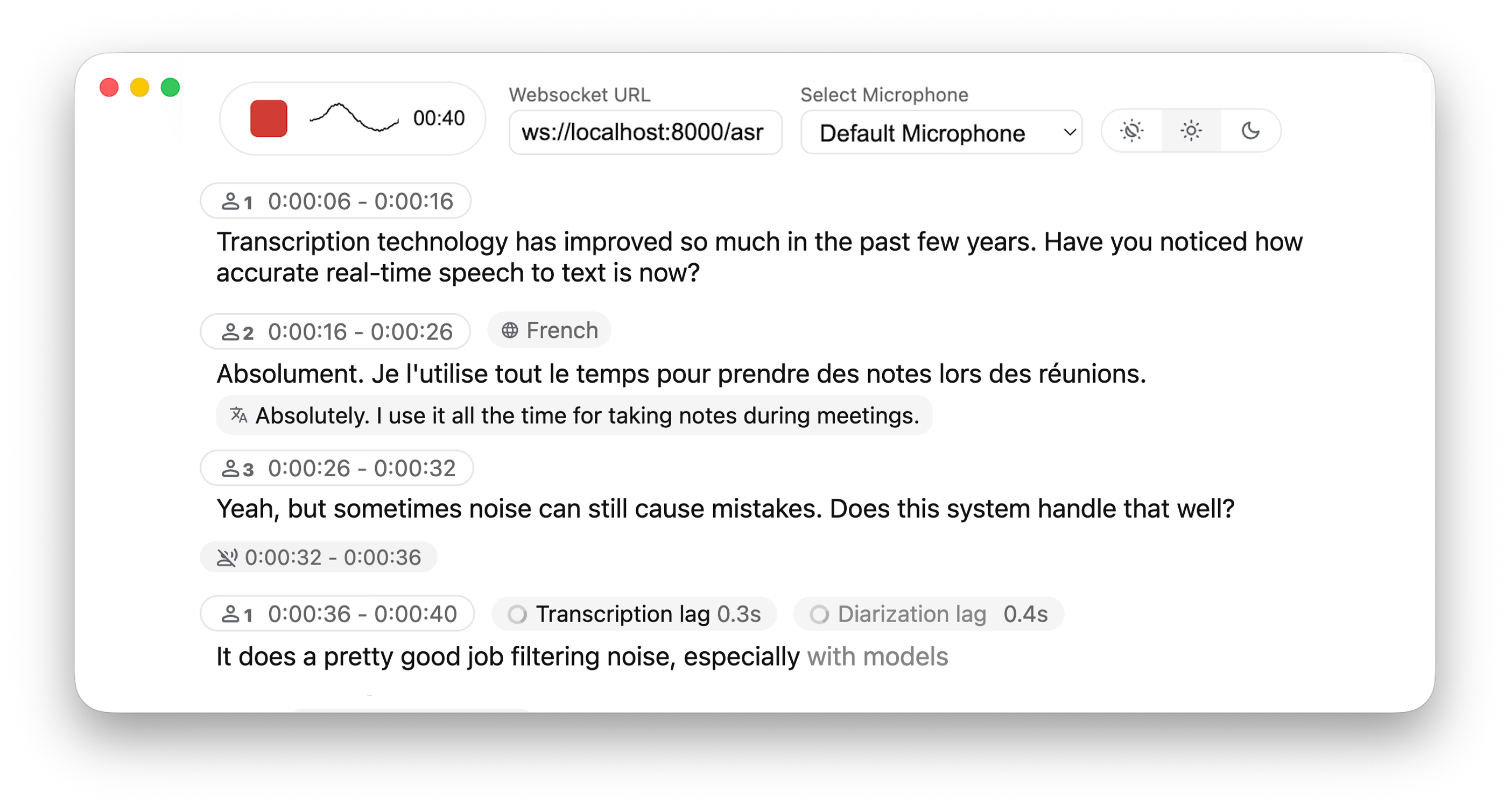
+## 🔧 How It Works
-- Once you **allow microphone access**, the page records small chunks of audio using the **MediaRecorder** API in **webm/opus** format.
-- These chunks are sent over a **WebSocket** to the FastAPI endpoint at `/asr`.
-- The Python server decodes `.webm` chunks on the fly using **FFmpeg** and streams them into the **whisper streaming** implementation for transcription.
-- **Partial transcription** appears as soon as enough audio is processed. The "unvalidated" text is shown in **lighter or grey color** (i.e., an 'aperçu') to indicate it's still buffered partial output. Once Whisper finalizes that segment, it's displayed in normal text.
+
+
+
-### Deploying to a Remote Server
+1. **Audio Capture**: Browser's MediaRecorder API captures audio in webm/opus format
+2. **Streaming**: Audio chunks are sent to the server via WebSocket
+3. **Processing**: Server decodes audio with FFmpeg and streams into Whisper for transcription
+4. **Real-time Output**:
+ - Partial transcriptions appear immediately in light gray (the 'aperçu')
+ - Finalized text appears in normal color
+ - (When enabled) Different speakers are identified and highlighted
-If you want to **deploy** this setup:
+## 🚀 Deployment Guide
-1. **Host the FastAPI app** behind a production-grade HTTP(S) server (like **Uvicorn + Nginx** or Docker). If you use HTTPS, use "wss" instead of "ws" in WebSocket URL.
-2. The **HTML/JS page** can be served by the same FastAPI app or a separate static host.
-3. Users open the page in **Chrome/Firefox** (any modern browser that supports MediaRecorder + WebSocket). No additional front-end libraries or frameworks are required.
+To deploy WhisperLiveKit in production:
-## Acknowledgments
+1. **Server Setup** (Backend):
+ ```bash
+ # Install production ASGI server
+ pip install uvicorn gunicorn
-This project builds upon the foundational work of the Whisper Streaming and Diart projects. We extend our gratitude to the original authors for their contributions.
+ # Launch with multiple workers
+ gunicorn -k uvicorn.workers.UvicornWorker -w 4 your_app:app
+ ```
+
+2. **Frontend Integration**:
+ - Host your customized version of the example HTML/JS in your web application
+ - Ensure WebSocket connection points to your server's address
+
+3. **Nginx Configuration** (recommended for production):
+ ```nginx
+ server {
+ listen 80;
+ server_name your-domain.com;
+
+ location / {
+ proxy_pass http://localhost:8000;
+ proxy_set_header Upgrade $http_upgrade;
+ proxy_set_header Connection "upgrade";
+ proxy_set_header Host $host;
+ }
+ }
+ ```
+
+4. **HTTPS Support**: For secure deployments, use "wss://" instead of "ws://" in WebSocket URL
+
+## 🔮 Use Cases
+
+- **Meeting Transcription**: Capture discussions in real-time
+- **Accessibility Tools**: Help hearing-impaired users follow conversations
+- **Content Creation**: Transcribe podcasts or videos automatically
+- **Customer Service**: Transcribe support calls with speaker identification
+
+## 🤝 Contributing
+
+Contributions are welcome! Here's how to get started:
+
+1. Fork the repository
+2. Create a feature branch: `git checkout -b feature/amazing-feature`
+3. Commit your changes: `git commit -m 'Add amazing feature'`
+4. Push to your branch: `git push origin feature/amazing-feature`
+5. Open a Pull Request
+
+## 🙏 Acknowledgments
+
+This project builds upon the foundational work of:
+- [Whisper Streaming](https://github.com/ufal/whisper_streaming)
+- [Diart](https://github.com/juanmc2005/diart)
+- [OpenAI Whisper](https://github.com/openai/whisper)
+
+We extend our gratitude to the original authors for their contributions.
+
+## 📄 License
+
+This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
+
+## 🔗 Links
+
+- [GitHub Repository](https://github.com/QuentinFuxa/WhisperLiveKit)
+- [PyPI Package](https://pypi.org/project/whisperlivekit/)
+- [Issue Tracker](https://github.com/QuentinFuxa/WhisperLiveKit/issues)
From 8bd2b36488bbcb3ae3d65d0bc48aa0381845baa0 Mon Sep 17 00:00:00 2001
From: Quentin Fuxa <38427957+QuentinFuxa@users.noreply.github.com>
Date: Tue, 1 Apr 2025 11:03:22 +0200
Subject: [PATCH 2/2] Add files via upload
---
demo.png | Bin 474195 -> 434699 bytes
1 file changed, 0 insertions(+), 0 deletions(-)
diff --git a/demo.png b/demo.png
index ae46bf9b65a67edd0a64469344c2d68039e61e96..9e2e51954bfcef9fcbe1978012c8d5e8fabde407 100644
GIT binary patch
literal 434699
zcmb@tXIxWxyEPm{1*MM)2-0K*5v5BnQ9z0ch@hY}0Rfc~FmyTcn=l1#Xet_`XWbc2wuC>-x_Veo&COk()j)FiS
z9y3#;8z9i(b`a>G9Oq%+%KC32-++%Jex|pfAdui6KY!TFZv4IuI{dEL%;=I$NESIe
zwCU8%3?}l!D*CE{uOz=D{{boQOBdgCxLh=1i@ALHmWhA6)k$|@8>7o&moEpL5)?Yl
zAGm(z*h@z#IY~)wPFbT%oMykDmpboq^=l9`ZMA~N=w}3h13!P*LEGo75uxB|$H2bO
zKCQqHkQ+D{o)G22DfNus;D7#-kz?KuzW6_{0AGl;IBj_C->zM|e=qjPKktq`lE|(6
z&r6)j?_NsD{QDReRNDXTQu{OG==6Wi3tEYdc@yk8j;GF7CapF)kB-y6=yJ_o_rw7S}h4=ZOk4IXCYz53^4
z{`qk1GFQLV9o~T(&(eimcDqMS_9{hoH5aoiiF&jiqQigotZ~aY>3qVUyka3Ob%}bL&2(E=EkG_f4qxmYji#y
zMB$LFnq+zN+UY
zBJ+wox%Bs-H<;hadWZ*OLXnM=w*7vWW*7ci|~9^HHJ40U?b_4tEfoPlt(JR{Z$
zYcd;MYpd^p)FY~9ZRQL{!>U02>U*kL+P^wP7|AjKrhMholILFSAML_VAs4xhxd%@M
z>o;nIA5C%QemBUAIz;0xYJT(UZ5MrsHVNzqF%WPi96+<}Mc3J){jCFf@+CB}4e+ke
zS}0xme|3!i-tE`a%N&2%qPmAaboEKL&~q~KqE7m^>SM*d;weT_fZ?eNx&
zuiSnsB@RnIfEv{KD>-ofT{ElwsGA
zE3hoMDX~m^LWxtZDN&NLN;JPhF
zy87FG4RS~p{Kp$87H}>F>4%br-VrXZ-8J4c2V;cE(ML6bj(6EN1TANh
z+_k(2TNInVB6YGNj{z|Ta~&A?_WuU5|7Au=2y0kAdC>Vr-JPJ
zQQHoT+>o+~-OPTWn=ho)>t?@IWr73x#(7-1X1Wd)w+AncRVlrTsG%(kw3R?A)EgOQ
zG^vyaM&MtA1m-fV6id6+=Y#uHj~m_!O)#TP-O8t(j=se>j|md!mn@k}mVcBRacsRb
zrnNPx@!Rh31jP#dK=(sh@RIrmq`@aehh%Db*7V0hL;?!%AJ`o`Wz%+b*4^p&!a~4Os;LC6r((7gqUiWXntsZB$J!tt-j8kAd>|MjOOZvq92r3EEZmq(PU*!i*0>?#Pa^VZ
zPF1?B+DPj2$y)7g_q7vLy$h9)(aM(_nKGbz_NRVj0l{}L!^BD{l3E^k0*5Tem*KF>
zq0H5#;JH1_eRe=3-96>TH7HmVp1;{@@viB9Xg|eZVds{E*Ef>bOD6GYMZ7UP}u#zWr|b8jYX(6&5+us3dkOn8nkdLBu5{
zAgR6Nnw_cO5!BA(LGi_i$i-9Z;Ukc(J@Deq3$de1GWT+b!wMHR?n?JK+~J!SZPk~4
zm({$JO}IGU+lO^<^i6|&{T&vxN|BuksnBm+Mnlh=;V0Z-rIW>Q-V}`>RoedpNWh9Q;bg0V;&cj+y=i;SQ}3h@pF{E8MN
zR_-9ukC9!s3guxxZs4z#EFUv`$Fz#tZL&%K&uEPg+0v*ZR#w0V=qN*Q8I;Z@Mu4t_
zF`bk3i<^jV1dbG#G_n&8GEY~3?0%s?dD>l7uE5r5j6Uz-?jY|wI5XM1{JDL2YY+R0
zu+<WI#+-Pc>8^xnlu;vJfAW^^rKN%h^JM=4Dg&bRS4&vYtL`e;b3Nc5!}
zUry`GL1d8d$W5VZi*Klau&KJ78Ptb$alehiqJy
zd~tGDH9+_2Vj{VN{>h782ti~k-y!^)`28kx9%l0e&1irLEYIv+e4!<{3%weKEkcu`QWWH
z4`wMsN0&1ncxYF^lW1v=W+sImCtqO{Y&6n5?hNN63!xSICM|(ikXVRYpER8L3sQHc
zm6ImJ!y`4b4+J-H7rgRL)PMs_FPIs5$L#DIO-
z$cL;1-T*JI?>5U|aUxU3`OLOw?*Khh>3A={)iAVw%rbJ*m7_~4@$3gTYP}d{_iY|Q
zN=`@x!)ID~0w&?Ep}q3vo3-BcW>Dhtq~_k$$5cWm-hy$5u#@$uux*sX1`m&*%_>Ur
z%`1&un8QNe3i4nn|MO`6U7xvG{lq!h)CW5heEkN>9-qw$N=8;D!YYF4{cOc(o~D)PLF2fj@!F3#hnzNLb|c8C5zG7^78G;A
zoy%##`jo`i1vuvy>V?0<8c7rHB_y5jCIJ5)4#MMizWNpUR+z_
z#oP4ZuH^Pz!q%h~OMM}z53}DzyOe;YJ_c(nfyapTUbR+vZ=N6W=C8B!xip~_tUS?5
z$qq6oQpnmAAFiUYi9xB;m%W@1lZ0WV*2!?Y81!(tEe0S0bX07e8{j!8=&y~ZmRjy~
zh6?o&$D}}Z=;5(T(D3pEaBg)@KG+u!v=d)>l@6Kzr~I
z;`X1}38TEcKUR-L79{hM@)HS`wf^)=8`%8K3iMSq*5kleTZD;ILO|@XP{oA|s2Mjv
zU3OLV;Ytv46PZ8M!_~E9m-*lW1lwD(;I?ov6D<$dq^=nE9q-;PShEsq{Bk39#!f2R
z%LrWXxex-q>mGW|p9ZYd0^hl|6h7nugfnM@=@I9jE~XvGwDon?13BL8L>AynHb%o4
z|JnVLbKpft@Ez727<0U2<4iANVAp;)7>n8avI&kVN>MkGr30&V89F_Pc
zQO)3d)TX&x{2|%%lA+hMCIq-9N~8?LsK%GZ{vMaHDM#>{h>Qo2ZvFc5fqt3
zi~vj=p-M|kk~jkJ7-o3y7Z?R2*^UxDN!ddvb$c;{czGhetJaNKehLu;oV4C3_+lW-
z%>kgDlnTdttuFDA5R2gcf-ESxj&eF!==A83ESz}l7us19ysx@GcJ#TB_bc@D{gLQl
zuKu_BD91|pz;0r|6S!$$D0gBKM(me9I8bQ`F4#1~A)cx))%dCsh(vtuBkA{RNthAJ
z&c~3c;X`uN~M_ySj!&w8zC*{h{o~yoa9aOd+`%p
zh1Y{V^Ed^p=FNo$Q$zcqdfmq!(r(MS(MBYe5zVw9Xrb%UXerWvYsDd-fKs0dtFz3Q
z{#5rMH&M?5Jl|B8=ZvGH2(dFoN`Js>@JmHmkElI}z7l+_KG+k$^+LkZ
zC;|Mbo0Y!q%`MUNqE}C
z5`A<4wN2K;@p-8@ZD1EPT7(PT!Cp^9U4tGsyjH&(EaexfgER?nIc#xKu}}ej?_#J_
z6+Ct^aZ$$yI7xLqBdpz3Bt&y3KKCse<^khNB-!iqE@BfgPOuz&|MyDbFL%i9J4)T;
z4iY2d9h+7^#QikVGq9gseuncZF?6bab
z^}`}F=RR=g4r|lQ4&Qsh8K};-*AVP*n`Ob
zrPhD%T#}qlSow~tRf5CIZIMXUs4CnSHM3FUp-Ndxs&pI$7i`1`KLt>0X+7~i7uMr^
z?x@X1bH@E!NuHzUQYpnwIZKm;;Z3=K&JlPdTRtzzUw0?v8)BmgY_gyg|wQSkDp4qVi&nE>%%uFz~n5$HJmQ8N+5#me4YiDR#x
z3rlr!4frO#NSeG%>=4y-CoFB0*80@Hz8|>9)fYhM$$v=Oo`H6CkQ$vYl7tz@%N5`*Zq1E%)b3mieF>V+{AxIEuFkWs
zY&)`aICh4!48o;t0hUGYWV`v(rZ|G4yht?`dbEhakpbdHjM~<+7@~$&+lh~bH~$*b
z6unSa@kzl~@H3;T%!q7S+3mI64C4i`DKNpGxfKcoYnUMLMnyT!@t#vc({-P^8#dT{
zWUk#v*KIMrc|S8R4U?5I;`g&|NOqf1RFo%eL}s}r-#hGqc53-M+`0GSu%8Mgh`R%4
z`rYy^V$i~>*_i6{)50CEHZA~iJHE97^Rg%?gszL)zWs~5681CNR#z~uideZy!QY|X
zLRsUGxAC+eC%XUSABNnctK)08%JEddzPw0h_V|Jr_EhlHo@bk1tCH2}_7H)Is9FNq
z^^T{Z_JR&}yu9|%7iT$=>+PAAzG0MN3U`-+uO2NHNF?0G8_piSX4}ul7BF10Hn{PS
zmb)>UkG!t3r!ooU3IUZwq6+&gPr68k*YvewE+amCiiKFaBG6L3M8
zKg}1=9zm~1M8H}4zmtHtjxQ01VXQmr{GNzOMfbWj({woibZw+AXCQtNxIv2G@Z(#K
zZXX0-`p#F8lf~*Rmu%W4F#^X@CL%v)WBp-;dEp-A>j|t9*}Jsm+tf-KIlD
z%?O^XcO&#n(r^#evSTry4W^K3Fi%fDD%vR3X`I$MVCQRH}4JKM-pGwthPX>gOKW%lt-c}rAUpcXR8!v`f{ABGzH>1@q0PGNa
z1x)%CY{MJ33=_)W-&=PR!?wzuN(p?|!|5Z&wHwlxkb!fwR~J}Li9q-hl#|>@^Is!u
zmFtaY^a^;oskdJnGnqYb@MafizC%cxNPaSLh|enM`RtH}ZOZg5tLk{_RYkZ@;
z5VBU92(|#SSbvZxy#S6AP(f2n84|_Z&K&QfXaW9~T~U~$+DH0k8&3pDyp-?E``|iZ9#1+-s(G-02tM`G#`h(F@(}&
zyy!~TFBaoH6i5x_cH)7Z6V-r^p!O_9FvDtPi3J<`viMx;Vk4naoh6m63R4{-$Hz`S
z#O_Xe;e1U0v+QA-E@dXABo6MFVP=T93bgakr?6Fuv)AA-PWrY)-)^}$YfM=b@k*a{
zK?OdzQ`}Sv7!3vDC4D*2i!>Ri#*@R+gn69{m>K=d49XfsKB&@n-tqqulEhCqKI1}He7!j1O+HS89e>b_RwwDmIG!kNhQIJ?%i2c60ttEc
zJIuFnW{bGBQJ*IUcE8ne&7*^<`R+7M$
z?u4y9H49|#2Tj;=c==v%VolfrKI!Hl3MVed(@{XxnER_b5TBqm2C9CZ486G5I;s49
z|9Bo3Tdau5#jV!2=OEyq^Ahr%$wKox^B0d}pL=Jw`>1uzPco%PVDe_XNG8BgP
zuV-j7j_0j(CW7M^sdJ(e&?OmCxU5O#INx>Vt5S8=c=`rM-)@7%!q?IKwIm5yXH~CB
z+T1TQ%O=+NiE4sAW2|PPo>)m;)S%Ec%mB|C_=(uM@SLkUzF>cX=iF99!ag0jf7dOD
zxG|X?(3n9JzCDk@qTH+21V%l!0t-nl>vYs
z%m7QFQ^GN3_6MR^$g;{VZiz%QxLW8U=pmn3)=YeG{lFl~5Xn6BLwhb;Zf
zYl#UG@=18z_&cNcCss?@2)^1%OyYQ@Avjs!r*_Ob=^9jJKui()_Tul%UOd=A-*OE`
z6!!9K41IXcXsa;xoG0yUk@Lk1+@Gvqjb>9D>?uIHA~cx3-N9XS9)G?J=PUzE*&Nfq
zfpugBEmMHJg+%Z#Vz;Y^^Q6X=+7FPm$r3|BS@y-y97LSRXv;J2p`!uhySaK*GS
zkcmJRg%v_%>;`D1SVWb6@SDVM{52iEuf_@0okNgIoBQ=#5O*N$WpH%>
zh2e}Hv>YfeT(c6@h3|A02h$x!9Cs^JSCa6)2^KwoQXTP-XB6yN4nTHjUN-n&3O2yj
z)n3uANz?opv4hFs&XwrW+m+~(MhZbw*$6L1UwQ;=ZUG5yBm`F)4p1u#B{Z0z?Ar)2
zPq%Ty1fh41lEIsa1=o#_C&$P-$aa4_@pBx#vap+osBAf}@7oLp6OmYFb9^=;
z8oMUN+(W#Ae~3eqI!N~Tr3^%J-)JLqU~8s1h+2k;)DQ1lPWNasiru(ed)ZYC74O0I
z&B3LyMLea7ko$S0(9sl4A}EBt(lBM`OC
zXc0M7LmMOlT@p&q&OwZLqu}|=m8s}o1^rhM1=OeN%Q4D<08KnxoYV@YOUY5oE7r1h
zinHrCCQD0kB);2VzokwRCA1WPa<54rw}J)mDvhE!y@v`D12SVk#rSLb7X_o=n!bl@
zj30X5c!aF$tc!lxbN54`L@xP4COYM+)Mx$!ML_5|_lOF61Cc{v`~gT9M8U`F&D)Z0
z>*Z7)Pf
zq=FVRJ#?r~Wjb*%vjN=jcaxsomFAQx^lhEn1Gvtuw5qTXjqk!*2NVh@>W~rfL1$*Lq{-G`p%;mX$@?9jEA;WFw2lh~
zRgBpVE*<`EO`m#Nt>r;ni4K4qWcE1g7UG;8)LB7pMI~iAtXyq%eRYmf5(UURjY1g!
zF~k>J(}sWPS>=l{(zy_-h#1(~91oz8(fB>~NEdB&8@leZCj$4Nzr9LoM*Un-xH9dw
z5fOZooGgaYR#zB2Af{@dy|6S%PeoDxEQK#!}$&NHcv3ifgXF-=BA8p*It?PAWpePqc)A
zo^~L0kK%^M*XKMpRw)Se*B9rx;Y{32l$Yrrdwii`d?w(lSO=I+r?x-S#FRRA&#MFR
zd=PRjs5jI7yr`?ULlxnx&{qeSb3%C$R(eK4z;>(Licvf*YV99=V!4Pv5M@|YQHqO~
ztw^eM_i6M=*KaKMt(VPw2;T^?-S8X~3mS7Nh4yI?zcaQc*FLV)P5MgUC@L<(r_;Kn
zQm$;I8P8o7_(!Wv=V_0;j13Q5vuXx+tCEp+wy{1Er@u1=MeGeCnE^x%%wDffs=WQS
zO60Jtup3(!n)(_)|D%KY(PvCz#3p745!px-|K*Sm1ebE-}_JTF21}vue|yFLy*hxJN6aN7eiq{K|$b3*21I*@S5=w@0eF(o^x!)HXJ8kos@yqytXU`wT`d_(}3?G}l7d*h3
z{rRxy<)C*VQhpCF1!=6bHqsunFE_$stY?OUpR`*H5b
zUKwDQJBDqYVYDwC5)obN>mSp4J+AKAMg60l%Sx&9^XJbmzTImLUu_@~S#%sLf)vdo
z>csX@utlkh`K)=9f_RGDXkeU7X%rD@jbw00&LDoMzoI8=GBjC$JdR=r1>=-P
zW(htnr$t;Z4m}QNTb*mAd*c<<`=&Nm4_QoD_iV|7WgBxwaS3=OlGRk^MA}$`K8(W8;eUzt%H_eSa&#ne+JUL
zI~R`w**WX>mhgZNPnZp$tCtkvTfw2$9hj
zd5?9-MnS>dZBjZw=B?DNZmT~J5m#qBgxdPBQHlrpqdY`s$3sVmUloJ>Hy1)H(Akz<
z8Kk<7=&Z~fWi#;8#XJhgTjjw(fe&jv1{~qjm!)OG!_6HKmaOrQHak~?AEDyFIXt@@
zFF3u~7mTKqimH2uutn*0RNM5ZMH*=H8Z~pN7DX0Yw%}OfEv`7pKGqMt&W9wRj?pN7
zcwd3K^mJ*MfJrFftg6>5Ha<4$zLjk|suVw|*t7k;EC0v6&(X&-%`0@4KbO@NYc{>0
z_Le=O%45$gH=dOU_5Y}!47Nb-93zA-9sbyH)7CL?B1;RJBqA=Jdh(yme?w-%(Za&Q
zExwH_L4PVD_PQ-WW2d4#*R~yI=rN!}e31+ejj=<;47xi_EX9FMD9l0P3m%i<2|kb$oohybm!-|JcvGOHU+Q0OR!g
z@tA|TtVPVC@Pe$bE0y=Cg1T_5(8fQw{QLpiTmpkqn1p77eOWLUT_4W3C1lo)AMh
zpZtho=hggSsMxgL`WiHn+k{CAJxm6F+&hNqeU&Nxa%ZiY$kLKS8V?zMm0r@Rr)7P9
z@z)C0nNDU*uKn{BtT~#N88f~VuX5}U_q0#!($$
zP66c9N59*O)KVSKj7?AVneX36LIcEaZka>6I)t1f3}jwsWb{6gv;MbP8fs_HZ0E%*
zXtP~ZJc^rZT>P|8$MYol?~GL2S_Il9v-tCxVs6W`zT{!YoJ}{K0T-e;-H6=*_oRIc
znz|M-+zDPvIAO>wYx#yzu$bj&*H`n6SLV9<+v)&ag}k1nu;KuN+mo%L=6JzK`SYk8
z>gblE$*`f;<~hs2dNB>YvoR+=)9N(C>+taX@|n$4RFfhS*S3Ql_~XPsu(eYHpg<&!
zP!54D@BjR=kJZ@K1nIn~Vx{otH4*FFO>fPr&~_^~e`d@{s|vt2Gg&R+F#phHLy;6F
z$C_&A7j62(PP^J-O^to=WH%eLQ3aLL?eA4Cv|*>460OBP_q~r2?Tiu$v&cNGcyvFj
zU~OUI-cxyV+6boQ?Aj`i;Ldojbl0BxN^^$0BPfhT0kbG#F2WXG*0d{9oqE&L)1XK+
z8Xe~bOuOCg-u?Tso1cSLCi=-q{{pd3KdD(RMUD}YGg`5d#vkqSt*jd9pkUkR`g#`)
zUa3Jc$S$5){+%_T!&XY~dy?<6q`oC9!zJv40F>^%1MsZDpcX1^X}3CLF-;^bZe5U6UE?zvkglu?H}B;rdry&I9*qZgcbT
zp%_}B3TbVRImCC>L8EMo97+ixm?zIE5-#A{x4oN{s*rVI6j5w)l*fkVPRh6#q8<7Y3V^(XQ|rAs64UpP_BlO*Uy9O&{h
zb)C_|k&f);J!(j>PVLpq{V40h2JJE#*>RhgSLa!dkq^t|7aLIv-zJxP^rUZiWVpDx
z6;@U%{>JkY2(KL{2T$3lb&?fz?We~=K1~SyZF`@Rh@p!l(j{A4+m%+a)*Z%xL>C|;
z-TeGMma~%60WFKJ@xNE{(=}#kd`&6VQ{wjIW9h-KjW0xYPJE0M
z+m_h0kuj4v!U&>TTigzIR@ruNkceTt(qwrK39s-JY1({OC~%bJ#i>p)TIX(vO>`{8
zzb&lO^iIz2A?G#Fn$k`ZyFW#>%Lpz{y53{dcN{CiX`jkiSXEAiv-a`e(H%zrexZQt
zankB)XHSNzdo<7np1uy8U}6J4G>4dSBPHOdmvhONzXgDB<~@~@*D_SxZF-f`Dk>C!
zKi?nM8>#SM?IBsA!N;H6Rf#pWelNfiIeRf%ll2r97e?nuGA5TW&gk*pu+~
z+YsJWg>c<8M`CsJ66&N5+xT9@zV<%0;3OM#;_)L+sZ4WU?aM(9p{)%okrT6rmY3Mw
zImWhXlJsAc;a-MT=%?{ysrbIJU#ndvqy
zK(9Y~lM;2fP=LqrQ`AE(^-@x1+tR}J1^W!BW3}kAm1u@AjLY+$P%1{bzCxbAv82p-
z#A0+I6N0{}kCb@rtZfhwSGA>d9q7#$eh`BAujYGUp0Mz6tc{J`Zva}X>+-R)v&+}M
z?w(ijnfO%B7LZRCO=q=`_#amX&+4;?#pkX@eZ{fZ-{^@_B&K4|Ul%=jJV8arwwndY
zW16VJRChJ!da2GKkSb$Fnw86WquB9+#{HNL8NW-{LW6EYV~wGEvA)MWE6&I4_=k@R
z!}^Ly+kYfiD=#c%PQHByuRhm9s|)Fwo`-rbbx_N>E`}`)mDm>z<~N_n;+Kx;`HOoo
zeE-sm`PdNUwgkXXwzjwHhN9Q@#{ve;Q3kUOh@(+NN|UV+xWMz+`Q&N@=nd>BoQeDs
z>=&81jA-BE^B1_Y0IuIpYbX@tPn^3lsBDWj9O5pW$F%Q(^IPwWxC%yN8~z|{A0)ic
z+c7xcK02WGYHIxw^pA3G6iLCr7XRo`HM$l{BPTt2llh=p-wS%-ZKJbY7MfI`F&!{S
zYREc-JEC0G-v$P#EiVDCc=T_IGk%+sljH9mebUjJ(_fRU&sQ%mEkR?YV%8gYWtVIAIIy$_UD;?I)z`P
zQXhayDk>_zT}hKwKfLwb60nKlg33xhLqkJh5fPDE0`Uw{Y<~T!Q~GPSPPz7Hh8{m(0};Ue<(yo9qhst5
z03PLw#7=PmHj$SBItFmT^t9f|{uZ$rjc%&S7~%(k46bLgWnQ_Z|BbbNeO!J2w+hx>
zAiMcx7*$*oMo$BPh3d5jmhLkZbtTiQz8y5`m4Meq5k4p0QjEE;DIUXCEpFNL;E;vR
zLPRxMv_iND2SaU=n`GpDo&GGuG3q|HUg+XVP7Vh)?j&A<%l^xeeyw{yk&l14f9=ZO
zhG2At1b{@BsfZWAyf#biO5C&i@Wb<-RIT%Vb$^tYTf4H_L!fA%};F@sMdES|x!Eqmh#ExHuPj1h|;
ztXx186kp3{;$oFwMGH@2vzWM#W}o6829Ax*Nt_c+`|v{S>Q&Azp9KNO$SIByqC*-v
z;*pcZh{hvXoR47tR9O`s?yOA;9E-Y-nu~5}PJ-W}1&oMZXv}o*c
zqne$>U9hxZnC2^sxJ>XX=#|z`TzL5VY)We0cfU5ya$blxHaSg!FMZIMx
z&45>$+scky2r(9kG27gAfCX8bBZZ9b(Oop7%1fX6AgLl?c#*n6)-~>%pM-#vL
z;2kQ$_}R&MBo!BgEzonRer7gWr{Z>vtKQ@{?ZO
zWjKCapi~i|4W~wkkL*6(J1Z!EI}TX@PimXl3u;>1C1}q8Vey!72n(>
z2m7@_o==xEbB!foiMZf0fYMz8MCb#4(97N`yqvGdtaCzjW&4XvOvdbV=9$F9iWOZum
z?wTX_Jy$%eIMx0<&E4R6
zbXZgMMUUYR$sEvpGqy+cN37DeRS)ayOJ07p;(EtzF!|KJgiBS$o&*`Q&UBL+Rzr4D
zJrj%>5;=`VcNmD7*ac6crpNQHuh+EJrq^|LPS@OCaQfXzw+#38aHivS#&Y%5<!Rc9_ZR2N|ePSt0
zy(;(-aYqVgYMJwsGb8#@XJU{XAo7477qpNZ*^t@97QVd_nVQOJc()@i%?~FbQEUoUQ&NhAIQj`#!12#D$=^}I
z1xP{$kP$mESY#=&;v0MT+x#Otl&_fjq<4+L@Nn4pZpgZ`rNxETI^A_iP)fh+PeUD0
z&T!3kIepUf*n{(b^In3?F+GDafjIlJk1UW;^Pz42Dd@#H>q*QA)f$5EDM(1gw;
z^--N26rbtwY&$!^G~JY8BktL^=tu#V3#Z#PpY;U_`?QW7?6MLYeQ^Mmo21gNVtU1NIV!uT8oceMa41
zF_@xGWY@2z;9XX1_#E|K_fMu=l6!5yPy4zMEx=3s=zEvF&QA14y?k=#Br1d>XiYSO
zS^JbUScIBB-bmZGLE4pGB+iib-du?(pQ){1Gvyq9X9|oEVkLt7baA`?MIE}Qs0zt$d
zv(RJ{atd+5ZrPUKi5hhZFMp?PU3l$F!bw%_q5KVV1Om*fLslxYt2!X$;Kyd6yU{Mt
zFIGZ5-N{>VvTpt{hYN9#>u_48;0E;&qVq!xGa-eK*^t-A1n+lz4G78Vzw*qks9|p*
z)1T6-!48_C?wJ0q-mKyQ95~YGV<{YM*BIn8J#Srdyl&hhGZ++dxCPYp
zMP4wf<0N5MkE3;0He8%O)5Ol3Q>AV_#2bFzZ;No__-Cr!YlaZ-j6eIU2pgI#8RPf+
zof@X4qw#P^9KUKlXRK31u!LgJDImw`7BOW&>$!U%kLyfKSK{(mdzaM1Yd4{g=~&fC
zO8n%XO2#9eVz&4ScEvlv{*=?_6A?|uF?+!?aX(V`#$07%R(It6h5%n
zB{@7DbvE^s%R=YrF7glg*9!(~a&O5f0S3z>qu$Pgrnzl6;(u
z1%KFjD?eH&4^=AaR4DXXJtKks31nN*D29N$vdv&to@+ib_S_#;nDB{~ccj@!sU)nf
zGPcJ>CBRf^(;@(6fp-%3R?U@kY^{l65kV(NaDcJ`M{a8p5>$kwDEV-zR#kTM?50REk`>-kcqKSXzFXX#A)-w(7B0bgv$z>_fj(
z=8FB84uI$_)@hCj9r$L>i&A&UUl4k?3+=eG<0=IIMhow(Yk#teG_>pTPPSQH-=^d1
z{O7iwp4EnYQA|x$>I21fdt*QM!jJn7IeagjjjLdhf`gzm#uZAQq;`VC++Zt0WUYS
zoSp%|uh)$^Dfuw+%Y*K~2P-oEjtzj@rIMe&-a
z@bSX)+=d~XaSPVUfggzZ;Y)?-DXYfYaY#uumaW*b^KQ@ZS4C}(Ngu}1up-~11-g;gCLoeFx9;wlPfotmyk0ieHTv|x4rC$B2$5i`4ath
zKfuSN@$oMhgzTN-f406U-g=7vPxe14;t`5bC7Bj&s;bd`ebrq43@+Q?GK5j|iGPL(U#4UtWwGv-M{(w!E;J=3U+vIENJ){f7b0PIAFHMA@f5EhE-Zo5QLcPP%wtfV
zS2mr;?m=s2GFZQz{_H8duL#r?rJ2dgn1DAgWBKE|&wY~$;)bkuVyBd}Gj+L&pp$dk
zjxeVXvcc#080z$exDkaS=sj4HCgF3PX~;}yn_flRN;To_f{GjIQi$Fz;Q8d6n3nCD
z;EU-NU$_ifxE{B}5Tl~Z&hvab*B2YZ?=tIVD^gR37solN@@1Gcb54kz-JXg#XzB25
zC3s52)IBo7Zpfs+pyukILi%lrPSdUPo1bM|_Qe|4$pc(3u2>%SsMR>}UH;qx!MZU1&_>b_f&!i3u)L9?!)5xyw^gofo*@+b
z|8{nSx1wRzn46pXjs6-6H>1fM>sme*Eu}#3>#+Ou=kw?Z37|NkrZE+}BZhG3hLv}A
zrJVEMUqPkmR|1$0)GM4nuA%pXY)}IF+f~W4ZW8-;*uXvj5aJf=0c#M0gbikbK$L~v
zwo4phLmTjG#|KCk(EHPCN%gCy-vR}A~1tgm-?>^A*Zs3a$8r#QPpP&^~Yl_0`L2oz#Et`p=^SI
zf<&-i`-xFC)|Y9yIOjjVpjzv>bx
zp+CP3RCJI2!V0N);yua|-*mc=DtSe3+T=;G>Rhx?^@txw+_ESS#+iM{jm^z8^Dwy%M9(q`tk
zH@Rx|5Uq!%8}nYas%l-b!B@Oq$exGDALM?WdsptQqsuJsdb0sY&>&=;%cOa3TuJt=
z=jCJNC{cTlnid#q6wPc7I8$f|6I@(+lBP(@cZuZJZ&h+$ES;Y`H}lrz>_hJL)`(dc
zD7R76ep{aX)>MDp>NI01+in6Sl2PG%(8X>y^(cG5ArSxRn+~oSbJ;>6Qgo$@;!;nP
zjOy;|FFeszah$gMOnNxAv9x0L=vW+w(D{q0;uFY_xvJ;k(RwsHij0do68n@(@PZ>o
zyrOyg4ya{+W=H>2IJpWG>CB>yJ}>MJ#_T(iYjFCzb3z#5a3)YOXwly%KLx61lH2qZ
z6h28hN%H`d*w+EyUy0G%9%FZAZl;xr82$XH!s+k-079~4Jp@)P_(!}m{WMT?1O0s5
z7|?X$-+9vW$6K!oQhh^p$cF1*mpzfNkB{cB(1{4eNh#BK}6Its&(uj(TtgOjW+^-e$+dcOQz15o8Yu@*MkxQ=Hr
z@WQ7~c|V+rk$`LdoXk`xG5aMgsC*T}f}gkh2s)GHcOYooU5JcfG1FB&dHZxJ*P4LJ
z_e*VO#**z{s|T7qctAgZ-{vKJS=%+!%kv*fD_Vc4Jo9|224a
z(8Ljd@w|saPprh`qk(uQH}1l7OUEGP)%_N;m(3mNfSxICJ)Q}jI3rzh?6%wQyIVzI
zvFDptRGQ~bw;dPzSNV7>J#_J1%=*jZh=Xa4LAR#^6&lGZ1jiR#sl5T
z&7FG4ukIj1F-jJh!k*-+!$=8@{qkK)y~lJ37N4VPoie2K!sl0Nrvw!YIr*G~1*`e*
z1lZYKLoS9!>2)69bIjb5Laec*7z=6uU
z-$O4h?ya{PM7K+RN=VY@Ke$f+ct7dH>5ecNNSxnz#O|c{W52-$dFtBQa_Wz0TSUyN
zSfMocfqMp$LLsJ7M#5pHQBqIlB2v+p4O&u>5(n1VcTJ_Zxn8=x-Y=XR#Z5g4_60$UzXQ}aAbLtObhhu04t|>s#>X>s-k{gl5G)-*h4bVGL4Uq9ab4)i
z07WvHaQZACqNU$N!qLhTfJi$4K5v!ZIWf7=(gM0w;czm1H5oydw$P&veXRn%-IJ-o
zw=*3q0aV2V>><>p;h#5*R5;rEuhNz)u|Hc_;?#*aWbz(`NO*oGr^Ob%nKBkM`Q`if
z>kpcocUy%{lg=c1tH-~#&_2Qk_`_xJS_4rWXqVC3o!LRh?4Wm=t5$M=?h=7E4p6G1
zbCN1f_n6mcMaS8qtlzYP0edF^zIhgwqZ_J1+u!$RF?I;)Zb@H&qIJSf)0ww3&~LB)
z&?FVSmdk4tRB(um;u4x;?yq5iRk(TA4&Mq)76my)Y+T;j*|8NaJ9n!L1eyw(^x56R
zA)Kt%0GB@T^RAyLlMaj!xv71ZOaXcbu3#scokl91lT*&w&H>F|oh3y%afg!380&3(
ze~k};Q$)#tEUcnPPIP~W>GBv}*f)`Go3e>BYkzP2=g{-3iVed1EV7W#l0PiH$~`)*
zdDB0`BqNdX0s7U>wI
zQ3*i>q(e#?q+w7}QVbeKNl_Z4J0(Xzx^w6ra0Zz9o_Y2CopZi_ye{L??cUFG$6D)N
zH{r-aw09Bc2vmda<8G?M&*L0kH}*f0#Zswe`)HzLf3ExcIViZ^rC*cKs$?lww^98$
zxhN!`nnd11e0jI3gG?y2HT0|MoC1|2`Ieg7z{9$?xd^U=Z}8m1QOZqsrF0-(g;R8%
zc?-9U
zU))pK*ZI1{G`W#jTLz9JnGo|!8AwBFhM61!8ARI5r=N4LEuY469O{mHY%qotSFyg?
z8=q9&!#t*H$frH~sY>k|s!T)36Y}Hq=I+~DM|Yn;;3cIA37xu4E_38fRJ)!4gm&cvzlE-0l;;Mm_({53@6_foM;xiW@;~;F7ZWh&994vQB
z0NEh~B0lY+X!spy-@?FYS%O?zza|Lclgz;n&T7=Cp(_9xmXd8UTFy`A=Co4*V(ZmC
zEwTJo(PiX`-oie38Q`xCq4J+6f&}4N(H1QjX1Fr;=9?+!CKeDq`G9aRoP^aI0+NXs
z#0-0ezA3U*P(IKqdomrY$`(KiMR#kJOgUXV{LM7?Tg9RdRHCw)(%W~Z1ICQ?Ydv@X
z>nYWjB1#5v!J?6>eV@4D{$*BS0hnQUCxA#^;ZJ(3^vbVlLWY&GHka|gOX
zo}(8o7ic&d`WkQH5Y{omW*3Q&`HgNe$10}bT2|>*Ka}E{X-tZWsgcm6xmGM0+zVx_
z_4=ITQvmisIhHCeCo4>qo3nj;}Bx9JBSon$HQiSMeRbcL916(U_FT)^m7W6m`CDru$
zwr?&kT%EoVl0iasvAjSg*(xwR^g|@8jQ72T>Fn+X{SzzqQ(57bl$&eo+o9ny)W2_8
zzfg*R5cqqO29-EO`>1g$Q8pquLrjHQem|vK4b-GW#Pc|Y4Z9Z(37ROkS$g+C
zfJgaq1HOy_Vfu}piO)r^X;+c~>0KHBWlpwxc_(WAKx-H73_G2=8ea+Yx)O(dBEpuP
zN!jJs^tJJBe(xX%WS3Rqkg5sHK1V)kMx|wVNX;a<^mln6~2{r>EX%y)YQa=
zkU1ou-3t?kKz16C89Fs00}@$QqdOJDn$^qi9=Nnoh+iiq1kv0Q(9w`fb|U;k8@Tf(
zTsXK@S0I2Yzq6UBEnKa~!7m8Au@uIpwhZ)NPW*i5SZ_cb8=hK2`FMcU)5Rs0
ziJ%j-j1*}HKSfi>_INFZeX4iHiti
z3tm06e<}Gcaz?Gq=>7n-n?4j}5R6Dpwtnf5A!9EM>|>VhOnZ6i8|xzIKFA=b}sG5@Q2w$bmT7y`%Lhh|`?)s@+G%@d#rFunwefVSNyRi&=
z5ad~AZEQCSnZ%=KtC6g~M>G!Odplrk&Q;swGAFH(mkK=(K%8Mi=3)
zTSe0hAPa)=M>dl`%H*_}L{9roTN3`L?Rs}fLm+^@`6>awyW@*bK=-W~4)e7FEQRP@Zl25ig^<`w4U5Ut@}&X!
zc4!}nT$lrvrG=mOa8&*!{FP|7X1^q7spTa@q{zfoxKdO4Km24j<
ziLadQHbH?*w(3ces5wIdwzT?mr><+m3xJ(5&ik16m50)1>OZI4(RL
zM*a|?^z%Tu%kwy|Cv_dlc(YSuLXRTi{RAsyTM4~ClX#o6d-w6e5c5Dg=DAKDR5GtihoSk<)L+j`jUko!&{wL^u8+o2K6vHO(TntxpXE&sDx9b9ufBe?
z5Xwp@82*#jKRmmQT9S%XfmY{MEAKT+0Ggf1F7xMDBq;<@+X*TOT)rt?3S{S^Z2mxy
zyqIhQZxcbtg_B_GA*Z{iT>i^#xYrpOtdM2`TnY4e=A>W0bn#|A7PAR-X)S=JQ1J2+
z5A^9r<#?WXoHjijD>T%*(@w{yuTAsWGT!n*0$IZ~Yk06>sG
zMGazp;jJv?u(~7s)5)I5X~baPrN4VhI1G2ZB8S)-+2+F
z#x{VB?gPa8a?{z0ASmei8?mTj%P9U!r{g1jj#8o9p>$o~1eCfgD9C_fl7F+pvf)OK
zO+jV&r!~Iqh-Eijf!NSBA;?v~uzgnulg0=AX|@YOPD)7}&42VN>6m(R|uk>B8--KM$6VEMVG
z#kfV4j8gjH(c|g`*Cgv*{ax0sgJRp(-1)(Bn
z6{0}!3cNQXH6NqoKXL9VO7`YT?8tsdMJPxD1*e9ckc~m0hu+t)nnLFmgOw!JUYm@L
z8vACb+C_F96W3B-_OSA{r1ulKE7+KqzO}U_jV)?#N$6#w9jj)DyXx!GumbNjEk`{?
zgkRLH5n*gH4Cn^!#qm`HC%hjLwUnFcWdDOY>cRdGKg~k@QjXFcP|FxrQ8MueHXL0B
zExzs}uEbt*^nrrX%JG!5sn^u@Dipf}bpbs*5rk6iw;3})DFJr7E&OuhG0|DM?m44<7fd6+6z_<`dv
z6a?uP(2a$T+bIaBX@r<#*LNnZP32!C&~bAXwW3~!SwG3Q*x5q`m$j}AB@}!3q9`KZBKjMENT57nQ^k#
z)p|P4zD(WToKNzBTk1iVvFhNYnS1X@mAV&7ax8C~O2tX-Mg?_59OKe?hqtS{kF-g=6c{S%@=sn>wiqPh&pNI24
z9XF9H!ZLTsVH*PA3?=fo3w>Y_5V*s(C%de}u5+&?sh2kKUgJ2TKri<8p$r?5iT=20
zUzM#4l>wry*@d!BbKT)tZE16X!IapO-4m~Ayf*0Tb5LVvm^{^ts+sZZw|lY#UN8~F
zp%J}`kNlP}JiiTT#$k7HDwzuo(62YH@DJ=A1hC=rL{LxDsyG;cEAdz#s_kmF+kM9o
z(Kijzp0s?CZBXT8+)XYGDtbH*y7)m?vxPmJ`L%e%y2je}_IA=SouR`kJc#pqRlMoV
zMKZb%$5ei+$u@gGIO8C<&ThWjR;>g>bmN|_LhWCld@HdZ`C576y8rHGX&0EivvV%b
zejFPkWHK6Mo1U(PvzmF1%l6i}&Im&Pt
z2C=rFvSeDMvrCTxwr@6=#cP-q3?q#x65Iw#IA}HbDcf;!@7Pk)@}nu(o2a!rO&u{Q
z?x;d%Vw?V@yHSpL!(j|JtG@k!b_cj{{+M==i~Ry*^8=r|$-<#^7^fd5YZZu>n}ast
zBO^9h-xB1$6nvwyFV2RV98({9PErIDF~$3pXFUen=Pv;T`=aa(MCMH1w0L
z)C4&tr4z*SYeq(%K<+@teAqp2@Ne1nu>)+7G*U0`EnVq#r$<1(^+wLW`0YT+uNtAy
zmKKV=+{%PTN{DBw480-~@ufK>6H+KSO$e*P{hXxR{8y;*AwTF7wHOHBzivHI|61MW
zPX!2-Fp|^KDXv0jJ?kc3JC^!&4D|m%#!_gX?6>Q8-9opL|gqlU*z_
zO?~_f$inN_HJopc#E3A$0C4bO_7JPh`H!k`$2IAyX}1T4D5vTLVk3Y@SA)Nhv&+xV
zZ=Yt8YUle{&!)?6!wE6u3_$qJ?-+tNdU%W5fnvkD9%QB>MvZZDpv-VA;KFgfteWwR
zDonL1>J$bi;|rBoLxPE$>+-bqX=6_7TBPMpvW@wG-J?T?mEh-!4wHeL&Jj10&DG)0
zBmY{PE8VeAJpq$nU*>QTy`9JnqCwIs
zl{2biDaOIwr1e2{Me+zn$<^Dn3$Dy6U6h%rIzI(+zb9vj=|(tVI^QEVn9|5ZH0L%9
zq<1WOy4Jdq0}8t6Wwna!ZaW8D%p_}9WM_^~pEIjxut=(tHeq8_N#dQYOF#+nWvd>w
zE@l|z@R~%B^5)#;GyW$f_ImqfTU+yvU&XX6Y*^d^Rm*xkk)P4ChTf`D-M0QVXs%{0l{e7LO6kQ7;b=!+tXAsGtLh$m{|0H{>s!yt~*s@pF
zO)f(vDJXx5CnQ6!1S5N$p4@WyJL~b}Q4EMT1?50o$T7U!c&}~3VG&PfY!;n9S$F69
z*or;fnfjo4`4EW^Y^b_bB7twiKRkS8dj55qTZ9{+ulpb+G+0Fznlvz)qI>j8%vxTL
zA8Sf1gy=NjxeF?}-`C3~_)L6OuAXg0^6s7Q!kQLJ{kJUHh#+S`h|>m|EdxG-vJ3a9
z&Cmxc61cO&2j|#dd2&x89hmF@o02y)tD9)z%aaj^v4b?Hh`!hZBdW9jw5po=deVMH
zYrYA0+O$6y7f4$*>-(bHh=rLsx^Lfb?wQ!LIH1bVVZ&|DVJYxX1Gwke~Q&pxtWa{K+8-0=hw))1oN+R9dPzm2k}2l;eWc!s2*LrQ~Rgm1n2
z;eU#LwN(JHFqB&}KrY;aC}}W@dG(z}_+b(Eq+JoX!Wju%3!%+84l+{e$@euHRmkEe
z)I(#n)0XUs7W6Di!L_<~V2YZCJf+YVy8GeXS5{PByB4W`x^oc8Jt*Kd$+Nkd(D%6>
zPA~oCX&AS-<{YLQBf~XZ)lk1Ni0rV9>OF9G`<+<_O==Jy?(gyLNOkGE(l>E&J$N>3
zYYzLmC_j}jpPCe)RhNPf`N{iuL++y4?^7BK!Ybo3=m|f^eHJa|M2%LlkGmohPU)S*
z=&@p57B1%$YwMf5q-Yc2+x@&AWH+P!k!LhdB9dVXT%*SrJ|wcsn32cX|DMW-a2ft>
z`$lE_`TH4{=_Ahlrp=x9UmD`U^u9mBeU@de6R`!ddr;H}DG{3w^7DK2QjuA9({Uc?
ze2%MU%Y?mzVxLFBT8mOEW}Eh#7s8uZn(9!oU!Q{!iP8ycUCypZ7@DSc1zJORPDGT0
z2yZytE_^w}POfMafEs}Wc{OYrk6XRh_?iF(Sf%SiDE%U+omv6)6qT==w@BgaO@wFX
zra>iCy_)jErC)UH!|^A=AbeuWdF<5(CLO~b2sY5-GiGeggT%$`_nMJuaA8a0${Eio
zB}M+&tT;JFKqoWmlA=*iPv8_@-o>a1)o0=d8#7ksg81rhZ32vbim4?Ef6zD)X8a7|IN5Hb~&wq9hU62ciMI
zso8AwEl=YD-#ODtz^60;LhG$f$7K^-x+f)W5p66ll03a9N7-b_{a#S*(#l0k`Zz^$
zNw%Ex8|&`+Z?uYw28NWQ9lvFGI%3gh_(lLBdom9mhbLWJ#34@hxLGUk;7Z!dr_Y!B@H~YP
zC<(^L-l(Mkx(v_{64U;N{rHB0X@l*(2SqFt>unT>UP%(=^))?Pf?_#~>JRSYn}*B*
zeBlUqzbaZD;_H{$M|V&S*GBk~5d~d5a&*Ww
z?Ztgr!MRizsqSs48$SO2YMCTa=9cHN!_Rtj8WY7w1o
z)Bel!FqWzQSwfTBPu7?S4|<{=43+1YU5)AjWI(?;TBNvn?tHV^bJytwF0jf%uJPc@&(^%=LGQlAilr17Yxyaca9AD=n~f+`d5g^L&N
z1%Xlf+?~7bz*nQV{@{|B!+6j&5o%HK}(P;MXdYe
zy}V9-tT~PcIob>;alOy~HURQBUPSRQL*|;H%vSqjdt?#x;Q4TXct?PXAxJTVEUkYGP1stugcbujV!j!bkKou58!L
z`5$2~>JA+6i96wo?W
z1b+jh+%t*T%9pH$WP#u_)$fi6OvD%IZyXUc{hmo6Z2ip62lKqCBMmFs1{Ddj=+ewM
z_0f`{mT_dabYFA!L%}nlW|uW0bJtlJDxPJURz+3-g2_)F3U3ijESMh&`q7xCoU>WZ
zl5buBIQu_Mi`WSbfq+;xhBHDKcCANQMghUWl-B7(r;GnB|>ZoqRP9
ztvWELHtyQRGBxWYz5b!)mu3S<#IZe4O?=njP_vRiF#_h=oF?^|sQ`{(jf0ve7Ph>2Xrl!+6B#nM
z)JyJl&R!&0Dar4+C&7I2z1w8(Bc`H+^*ZA87d@r81!+e@Fv&M!Q_K;y_8V9}0I{UU
zd+T|F_GhY@K~mS)JFSz>_iV&qK|LkV_FqJqvFvpz%uj!Cz5Bi(4PQ8V<^HTp+781k
zu$JP&KJv2dvShzyT2$}hb0neC>2@G-5D&!Dd%uGoCX&I?9{nr5isPgXJ?`esFcYBr
zDmqSx>iS9xS!6yf5g5-2^SQ@L1T;h69}?$t&W6sHa7s@CnFRU=^ySscG>nX|STbSu
zwnfhT3Q@D5N=RtOTBSc-@TS=O$Cpzr@N;Zzl6l|m)4r||L8GWp-7$-Do&dER8ShYP
zsSD=j|Da74o|4KIQ(vtNq*yJQCEtbnaKujg`X`xh$5M;zR38eQEv9VV=I9u*W0T$~
zA@ZE{p{z`kW4XsLpOa|PB7)#+8}3cuOzc(e@so2oIMr-74{vPXJg2oNpr&W%QsS*1
zG>Oi6YDE-%t?=%fr8lLF|E-QITb(4SFA$6ZXwwVrAr%8cNj+1uE*N4La}6qc
z^nADfxA`G?M2f=dm1?Trk`}#v!iSHyBuKVhq}3nUr7^~%YFJ+Mo>4fpjd*2EzdM5i
zYf+4UG<=9lC7i$#s?hh6!l$_&BC$0PTj%$-hU>EPGaIxNi0+Cw31yDRt~;83Pv=%c
zjC(&ECZi@qSKi9KXzT33do`i&;G4(bIcEV0@><*M$LJKp(v#;cVKRjy(~a-kI6s-VGWvsU#YzP`ReWXV=UER^?e`Yscbtesi2G
z^t`~}_drLYMNnpgTMa}@27Ncf`(QoA5fAH$z|T%xY4GAiOA3*Sr*glMmzH?DN%0cp
zlEZa)^o-%d3KGQOGc2M*-<%^x`CoJ;V(gGt5Q2z9>G>DPX*W5IO
zLQw2m-&~1je{Tt<2-gBc=Sem#tF)VS*eLT=+EYR1@1tMjQr*&&5ni!1)&{C;Rv`@9
ztYFjG={U;L=I6@`GbgUa*4}7gR9{J1lT=SG`Yh$<-l(9m#2#%B`A=E0*4X=R#u1-n-)ZdeXcL9(ssQW#4oTpd&g{8lvBFryh4JwkNOFC`E
z6dX8`|L-v&KrsUv;M%s6M@UP{J#q?)5#z?{@bN)N#>EoKM{t4&6+>4k`A>I*h#wEg
zgjAoG_t_q#l`)sJ4O%-rQxvz%z`wm3mYr`tx0q?H8>3V2#htT>HOs$zf5tW%cTQ#8
z8~8MwLRhZb+|z%c-?DolNFWV5lxO)_H-qK=NqHTqL?OHCo0@gz88sozPzHKT*TC1)
zYrssnh^R*;<(u;^H&N0#ew0n+-%+-Bq4sE?-E79|%Yfddd4A7jT~J9UpBCWQLN7)u
zfi$Md0vB+?QYwdsVfugG?`eNyc0(gX_z!d^{1jw>E5~t`r>Cd9m1_CK*DMf_ac!9`
zr*F$nS39_Lf?mge%v~~?lOYmmsn!r1G`i9^Vj~grSvhF}Yi^W)>W7(Y-TdU{nd8GA-yZp?!5b1`1O6)?
zCvJv-ZDlqb4C+_R$^UR+(N{r<^7?v`i`|vr>$b-=zL!>zzt5)UVutQ>+B+C1C2qc|
z=6cH%|2*ELUiSS9ZD8+Lt4t<$hjW0U-Ia5E9QT8B7Pf#L1-gE1%lCqs@PLmuh6`>^
z)!QbGTKgIRu
zRwGb~$oloe7&A&CB=SPgbyBGm9o@e`>Az%5yGoz;Tp4#PUFUMHS_NQY94xK%zXKnq
zSrl|!-vSq`dl&fhaBe&T!_4DoPmCaNyFFt&Hl1$1T{Lxh`)<1t$xq^C&CCX^N7stj
zs^}TCXSt)Z%KP-)S=4}0GV{aHDqBABIZLBws+&#gQ@qRp-<;9Xj`yCYyXvQ28?xd4
zIIQeuGEgBx0(qNaJ5c{;Z1b-aqO@&qZ_n22^Y&el+{NQZU}E(=yc&t4Q|_$B1_L|L
zbCSbL)4w9G2OP2iZ5wAd%;lW^7!ZnI#$f70UgwE70>;LdwhI>t-#*JUc8ZkzEb~Z4
zh-`@{GkEpYUdX<+!?mv@v|OpZwJGvG`}%6EsSk_R+qp8nQ9+C;Ho`SF4vqBJEJ!~w
z4Ti?s1muL!T=@v}9)mlt!9xlQ4DM?G9dMTZ=e3zavPD~4n=RMjvrq{eAt{($fiqWRGlNJG#@?~-^Dh&y?iR_*9qjZEw-({nC
zqj2syj!ucYaf-(huY2+iw=UOW(l*~|2xtS^y%0eUymJLFHD2@1l5!eT;PEk%eC*_b
z6v)-VsQ>>~C`xtD&(DXD4v@A{0~w3PnDVc!h34yGp^O1oHY9Y9)e=N#O;H?y2l&(v
z=P-6ADrvY@OZ6ceT*pYmwVPL03$ra}qMG
z+(o+gvmO1Hl*aF-#d6L`UC>=7n}e8Po!QGi*!+3T*2i@N#Mdwu*39FZEB
z)x^C*O~714Mru^_8Zg%5BUxdlUn?u)b00$EWR#w(+r(gYhdoG4UvY5bb%~J6+EOi8itzL^E
zPqhGefB4xD
zJI&Mze^hYw_GZ`|EmRas-Tn~b*noekUof+|psIHkxONm9Uk-b!4KV2fE*8N7#F?i_
zBb!Z0fzuLSW13iT9VlqZpmU0+N<`^{HK%vh#s2YVk??D7&y;7?V!0!@V^NN}HPt0h
zaSaaGDj72ONkIJF!bXp5mz8q}DLbK(*
zzjuxeMvE5V;+LCB=m)=mVJ-wVDwUul1=r%ffzjfRFEY;NlA(4NnW0R5L@b54(wkZe
zc3>9iCn}y1(hA6g4;vU$YFGu3abHNUQtqUAF&btZ#GE;3Jvv4nGm?d2KJE%LNSX8)
zRxac0SxBg-c3haOeh3w1G!;V*drSy-`8%;BO!v2-kmt^=
zXXIW?UwwhC8=sp8t4Az=L(~coo&(W>$EFU4
z1ms7igVn^i;#bSByAI
z4uEZo)0E6dzDzJoNl=6DY2xkc$CB!}pBZw#p8V)67;|vpVAUFE=d-VBXULD)S*gY=
zE_lZYNITKr2`)po?-Y!b{$mAphDL$BV>*8$AofGla243aV0gjE=$4t4(H-EIg11Ne
zcSZ7`H8Ao}wSxXf4JED7mVXDf9M+I0KqPggB-%|KOQJmmGqe1ZfTPJX?S++k0-xVa
zybY2};IWSP*{Vn>?$_mQq4sg*3q33=+R)jbF)WY8mt$CzDZef4$%}WGr^x{WATi11
zViru=ePJy}1D^ph`>x=mrQ;0LguYdH0)1Gq?A3N9bIj3t*33l^W-Ju$1YkUp|J%+y
z$O>F}_*^`vD`hNjEsDQjC6;MVf5udRpJXqIf9
zf@!S61F$cuAY+ssqA<|L!)I}U4=Q+{bJThI_#&Jrvx1R?)DRnxyh2o!&y65%uSJ~3Sf(hJJhTzD3)z+5BXGFtOffn0B(>6
zLk`#9N$rSHpznU*i$&1rzBKmT=WeHdo@O
zD&6IOIon5i<~)4(dCP+_?KGa`qLTE^PTh0ljC#3DyeC1~W3Z@$X$P5m+XGd|YAQcm
zwbu@o{jk55a|fH@5Z5=jY+mWi>acg-3Kaj!}!ev*Ksr5E8KPCdDM1FqjK-aH$**R8K#G4t?2yRVaeF
zlx#JrZ#Eg~;43LaPxTDCiuuUHC-S4GZuARCNr$XbPPW$$TCcX&V(KSSzMIqMUcneh
zIgxeCmCH$I8O;VhgzKu61(JSfy&K9P?&0NS3Di#a-`~Q&l*<@nzP~R;!?N@3Ce-^@
zlG+wj|H9QYsf5de^%n!NRKIqi9+S9v{tT(l&KDw5EC_CQ%_Ynic`9A25n#YgAouL0aIc*d2QMTAfcT|m5rT5}dyilO0qdVjP1SxNMzXW_VwY+l5!f*K>uKM-L
z1p?|BTqKc?#0vZ(Vx0Gs-dd=J>bM^!WclMP40x!j0<(J}P-qsg(MwoiR73+nd3^4B
z4zJ#K$0(<2jlt}Bo|{OM3w!Pd9W+Zm>wAfoaOO_q^10;*7oJDtfOtAupo!+SC}=hB96BXX5R`
zl5G-oW2WUcxzSMO@11_39nTR_B0p0yjcF|8pL<+&j_kCKPt_cpEKy&2^IZI@$3SfA
zy><*;X@_-MvR>}<=Mxaj#7X@k(kb=Y6BX_nWfEB>zXX*d-VBCO
z6yxUy;_x@5lZ|e$e{~!bnd>r5e`muZVyF+<_%{BDfMItrY^zb@B7q{m3N)@Wp0yDt
zrcuef=+i?nE7MNEYA}_=}D}ld%08NPI&o*
zGV;KGVM2QeEKp*n7R^$iJ+PS!2?HBhB;WNboXIGGO$pkg$UDqmZ9WI8V^rSB#ldwo
zCSSXuwv(9d7>LuAw!!~|-U!9@*uO#e3eBk^)UQxn5nm&K`@QBJIeXY>UWB6_^3mib
zRnnzI{mo(TsE5?gY<0j5V6h#TM*~{2qZJR
z)5)(hY9@VP8af_XWKN~KO{yg5)?14$
zYX|aLDZvFL7UjCV9h*i7I?0#dqlV=6cu2DOa@bBy>{l(vaye6(x;3x|x=rGfnP;io
z$y}bVQ=LQL{_o+4V}7k|7g;9U4Ty=bvmM`^*1sX@FZ!{u*Vv=p$)FsOLoFH{)Or{o
z(k0OVPgYHf6^c6$fl-FJRy{Af;}DxHcY0a=F0XN#oO72|M#N@Q^B`#7fej3Bf}q+Y
z`iRw{)*U^XxZr-CmjG6>=KmudBLAz#J%&5uah=PSKy4>ul`}MqpK!q7n$5sIm-7yn
z+q6?!V@=Y!6lz-pI6wn}eehd@}EW(n=WUq9bj#IvgB}aE~_8O(Xd$
zFwhWm#Heq0yQ}I~>M_3sW7g{ISZDhDGzLMjN^JhwOAK;71tI(iv4sg8
za2*g_59>*ODv$EkD)wA6)VEA)O!l3AnkHA3n2i`H_=ZT`s=>tXBi)$!|M}lE+n)fh
z6m`SO449zWqR>qrz0OG_Q16aXQBX#dsf2C*RUCdnQrGGr3v9Teje5yHQ68;OZi!@6
z5_=@pJsOMrCBpq~_#()Hl3#lba%6Q1SI{*!&vMQ_tVx`LqSieuO@QZ+4&s3lIU2k6H)N
zErwIJk)s#*Mt1A~Hcoz+<|~86N0ZL=Q=^lg1Ady<*an%C)Oko>*;X56#7=zUPkM$i
z;<}pUj5Pi?s|^2xks0+p5_xjOZ!|PQ75r(h5)@7G{|&hQeI2Q5J3F479n^Fnc#Uaq73gvQjU_b6RkletN&07{~Vj8NxhJ;tV8dI58V
z-~TTl#h%ih(cov&tqBC_teKs0pkjl3MBvZ?Szx$IdJ7sf3yST#-`J3_$M}^|OfQa?
zR3>UL|MoK!SxYA}$wl9gQg39;?WD$(Q9*7I*W-Xq`Z(;j?F29r#xJr=|lUwM(OW)5)!k~Fy_@FrPV8DVD;LPDm
zN7CC(?H3<)tmoykYS-xL8!>j}+U2o#*0Aum_sdPS@5xI%MsRg=WFGvg{C-tOa!0%_
zq^QxDTqM^h@dK*Av?49Z6=SOak14gshy|Lsh;|7o{+HDMJjEI_C@2Ab@CAo%LSF<@
zG}TF*JlGCUWQ+~Zi7Z&bmH4dgXsm*s72J<#X$z*bQo}WsF!o%TwUKBZv7i2r8SP!S
zM~A#Xx|h(ggvF(w)P=
z0XdtJ;-8U#N~#|lS3?W#{Pu}exDD3h%w&AC16#&^wX;Y_zms3#a*>w|&)z(9WlCTa
z(s=1u>U!ZxnjG?{RlwATSkx<92KKtI{xn2+X~q{$6mqnGq}qKB+j{man|ZU`ptC67
zcse=@{`uqw($IuRA>toR;F~I!s0e-p8zzv4q-`a8di>_02z;&oZz`#vLImrbfsu~A
z05)LCnD4=u|M;tC0C4K%1Z3vLTc=d==!qs-WK}o{Kr5=I`(iq)>`8Mi@z1tWy)|XE
zjSn@9aBU`qEPC*%`97b5U7!y@g+Dq5!!?4VBrm#NzjD|WK6G6?7L7WDJPd
zO)~a&hR+OX7P*>6jL<`B35x4!ZtTD!e?rL;_o|;4yLeYb0Bjl%TRfv5jyr@F6m2$z
zL||lBagT?c+i?pu^S3H);KI-I{zbm_lo!`{yxb&|1_n-#lDS1=%BJj*#u7?{la+2x
zYaAzFm>h+-tnqxggmnm2yf9(@JV4+DS^A7AS$M?>b0b5ZX>GSm@k&K9_&f>%sU5(R
z3#d1*q5<{t?(Iz;3)3FrCV19%50${zFGf^$7Fo1J)*vg
z8R%4Gyb8NcPuAg0Nu{iB?|@x+ZFS5ITyU_j#AIO#PUpcK=2}&_{yUt-QgM!RNgzHD
zi-?3v_Yo~qj7XgIa|ws{ydk>XHvcZO=+0vV-SthRcH@tclm^Q-AK`+k6>Hs~c
zqEuktX~l5h%+krZrvnjp2m@ld%m9zEB=(OA{MU>qL@WPbeqeJ4uzc~tTpm%J!r!;Oe!&|PY%mz>6qxkP_s}&Nu7Rzf9ah?pC~3ZQh%5`F=IPpZzA)o=tnk6yRF`L3FNJpefwb^?nL`E
z;(mYt(N~+LrC)K=P|v3zQd7((_OUd@h$^vQ!0^SmcQ^8oftf+x)7!hEj^lq9AjU{6
z3N^uZ$JiLmHIJBBDntn16ISSZ$SRUJ{ptFrT3j;^WX6o+kf}gstjbm(>bB+Z4}Y3b
zuTAcC_hUKmpx3z%jUTev4#4tPaQbyJO)dlC8q(9WVz$5ajmAHvR#HdQ2KvW)FHY=N
zbX$oJjR1tPni*N|fg-BVo6BsR-gp0E#UCI(6pI>`XRk0KE!`IePK_^LjQ)WL@DD0%
z-VGFYGby5AD+L4IBl*I6g&Z8@@d*@I?J$e30DtT;-*c*A`%c{6U@iFUP3c&zVbFQ@
zNwp7}yApY}P5IyMU8i&8=o5~9@M6tGNaT%!u4JkZ<>Ar~-r4z>n0upO{~~8gHEt)=
zEWqhK>fUxu5zl5h@5aW*Au)R@VRkWrgBoVMHp(AZ^q2gN9;Ctq42%r&;1p-8zkhqb
zYRMHOp}U&Y7vv?S$bk+Wc@*e_6j9YE#my&pah8t@U3&CGGx6o5>p7L+J!twTHn5H+
z?CPnYgTCuV8}Of9?MA^0VkBgpM7m)BOHhiaValpep~>T@_{SzI{7|LLocMz-Rc@NQ
z^<&q8hnf>VYHmng{k(pt6qg_;ojGzOYyW8C0C
z?_0RKKYcdYB9n<0^l>f>8gQR-jpEBb@LX6tQhdB&m~4-c!TKJ_eh|<3CK@;@*bfIV
z@wfzFGTP-~P>(LMziDDze;-1AbOMa?UGOJy9C(R`ol{A(p5RHq*q*OrIMPQ`xQOAZ
zN@HAbf3D`K;K&)9ru2G>b&=dD$WlcNmP{W)iw%&9n60oqf|YyOX_j=piEaaRXb%1l
zh=(^vy?S%v3w8zWYX&4`Bl53^2rtD%y<6&7k7e`V)38*GZX9{RBcn|!EQeon^7bI-
zzbB)H1hr5wQHQYu-LYyNuR=r&m59gmdGUBNL4(bezSx{cY5}&^mzf@dtsOWT2}gZN
zJ-7y^SP5_v9z|BXam74^zcdc;isCsGUgYS}ha*2!Etc(<;eNdXre=zL{k-d|-e
z?=ZU|cO+Levp=d!OQm@Yjd&@ZOl#NMW771>Sp&qrOqVFk*$vaZHEx#R9vP|X_(4B|
znTjQaf*GD+`J&?}xUPRi44T%H@-6my_#BFldQGj$rOKV8qZXq3
zUq+yfzVDNkeF
z#9V{0s<*+hI*8qTl7mMz|Kts;Ym5wFLD;_<3lJj2SRLZ{{II(!%HZ~~Z$PW9buR6*
z5>ktPFv4BDm1ma15`o*xZdG{p2>p
zj!_)jY(r6D047c`cixn0M(GiLeaOH6zfRhQ_uN@^b$%6fV2{H*SbH{iqD8nz7!;^f
zC1#=3Cg=W3-zc|%d89Yft@jqMxR$Dd;6uA1g)b{+J+JqCu%
zDr+h_6OsVb?6^wLV_lq~JG)^htJ(4cL#N(p%_jYonehh?%|gAercV*_QL2N)F=YG^
zK*O)Z`3r;tY)lN5M+L2Y&N7hRR6AoF=`v6!-oYK4HuQ+%zi*gnq5uK4s#*?;Buyb=
zV9_Vzn#JZLZ%=sE@D8hK8qdJPJ0cYa9`RD3c)#4yOub{-<`2J2?E|TAQ;T5$jdnl{Yw*0FIJE>$7a3=ag|ciOtytjR4h@fOh1l2OG`O@r*QW|JZICxrl^hDc#C@OBz_2G
zOGQAp4CK9b1a%!FC}cWnzrTn_tk~1vpyOxjtkEkjN@grIX0BHhA3!5DN>2-lCPV+b
zfDx4M@8=2U6gz`YDQ59HwD+yw)-@{}mhb>ksDvH)PI^j)u&eK$QPbE}w6E)rpLl7Q
zeUkS7QS}y3QFrV6_aLcADcxa!h;&JelF}ebH_|N~11JheigcGW64Ko%-Hmj24>0rJ
z^PK0L-}|~$aKUmh^WFR2*S_O(;rWEqNL96Eum}$dQ8aTA-{%bbe&?Qw+AcxKRl6w#
zmC37V>yJ!LmjT?Hng-vguGaS1)}?~tpHP{si`$pS3B6FJIrq^~>Jq*`VF(*Y+kiu<
zO|UKf7Cnty2#wo%cq@H3e}3+*_H;#y_9wO@HhZ|C#~gP0TV_4#8?}W=JB4AP9a)Sx
zm0;>)eP;gSKk_eL>||?(aJLHBFtI-$6g2aQM6;&DXcl
zU#9R4$q{$Jqepdu)$)eku54|%p05P+7j7$uZ?80krTVMlCkyAp{`+DXAO^i-d2h1b
zR^Wzl)51*^W_5~CZ<4Es;N?;_*8lMa?CEsFGw9Am{8Oc=G&L8+aPH(r3iL}#Tw
zK55*T``ZPBJ>SRysxQ^t%0)ijo
z`Q_C{YIwu>jMW#m!sGW~otzq
zY~}BXW3^vHZG})dv^o}2IfQBfk&#TcN~Vo{d*qJjo#BDm8scYo&-wg(WnG6zaiwLC
zI&BM69pOAgXSZs23JmR2^s)VXAN>1$?Aziv+aQ0zgKoXS<_~e<|DTeM-?6Jk0~||K
z1B8N$8+nbjOL^U}8W{bV9IH7J1K4R)!#x=2zy&~Jy1o5(CWqK3rR%dzmUR?Zke1rl
zg;(dr9G8AqHg?+OB%bt5oR%B+!q`lq1z69a(hD}RU*wWMg{mKf`
z?lCD_@#5HjGwPh8)c{c-U5AS|+>I>lLLZlBmrEB&(QNSG1rCycVcp19HSiaG
z4d}goOG)AT3r3`j=43ha8SY79D%NUj@kDIlA)sL(1>LhPpqt6
zZxRIzZA4!;z|$%P47$cQV1vu2R-vFQ*EQ}sDtjzyt}t4J!^!>G`q<52AItKUU{aU@
z>jG1-`0;c8thIh8g{PyX$7%tNZ)**mlZOW14Hui;2nU32;xcp!w&DGhy%}cPu^;@M
zUb#tI>PfdRZ1!}{eLzv*pq;|T;v~gH{1SY9W+dj{5ED53wZG)ZG=%rqXKy%z##Dn1
zgqh(VNAwBCV4+Em-DllGEH2+o6dj&u{PicInr!9`_aIWxPmdcRPC0%X?sCaKXPSwS
zs{>-Y!n_)xDp$?~ZcsKQnO#&3M`kI?VNt*77M#Kq*cO-v-aeT5F#W-841cm9dyuS_
z2sT=VcciiS%WUsA6DaNU`X|H(UVU-tvrhWr(3v3_41oZ0<~8%h2kVThZ$?dod+d_C
zWj4f#r;`dd>MCHqa|h?N+x!M}8=})6
zXEz4)LygZ5IzswqNxuB|@@>Rp@X#873!0C*!j0@GjX~Q<lV2vQl?ZnT3k?Z=T0GG`k1@MF^bbiJ2
zET{njl9|Nc)}&OYYwlMVZV2|LjT^(xwFE}~ggg;4OToFOqu%`hItp6hqQHT>8X*@b
zo7z6kKgY}kYGU79gnv1S&rK1n;trBMRhpsJGwUQK#0%iAA`G;hFl_l!UK9#NeVw0QCo~oXcZp
zR;`K4>ExZGtVlka8k%+0R0I#Lb~Pb))jX*>;%39f#*>Ev+}TtPJisux$bmP%=xv_T
zxU(XpxZ#{KM)c|t7S)~ew$pH
z|0u$lPgF#e=0`@)wd%?129t$kMJ&H_NPy59UsN=_FT-dJaoP^|*dqw&ikRkbaf69~
z<3nz~gKa)D_L=Ymo})WG-JM2k_UO;C$G-H|Q{>vNJ-}Q9IS=??7KKRTI1mR4j1oEKNnM5yhx;4@=U3EF7zT!DGuun9uESCDjslhqi$-t;pM%<_Ki
z=b%ErhN5MFtm_2-RQJi2@Wn5SnX`@Sq#Yt=DrxKGpPSVRghGD%N`ae_e~oRU-V=_7
zDZEsoy!d*y0&j-jl)sdLew~5eERYr@+Wt5bjLm5Y+o^8m^^|btTYpn(+Irb9KvkTr
zQ901irl%jh_4?}@oi#Mzy_R$L%PfAi*xCv2(n4jY0Ch
zXl4MHz1~;O=afnKY)qA8qjJHLH3=9iOu6SITb^$egZWkz4%cd;=$Am%#e(O`N=}N_
zXfAFWA^*G=cTpX}WA!B3=hW#`MS2PSzz6y^&*7v%|DQ{YJY+d#O~>cfY2+Q*QQioIPa4@XOLyX;4f;3p`A1meC)p^x*B^vTnAj^cy?<qWGxfpA47GN<
zq^M1ZloFe@qID6Ul@lOF$e&X%jcYJnrrCY}>K-)EQn
zRuP;?N8Qd65Vm(poN=P#dV6;1&Y5xW8TUo=99Cv=9N#Yny0HKS52{?8Va;MVbJ
z!_z3Q{y6yai1cwxKR)^pQciN^3wx0@^ZSfjeYPfB^xE@T%!V!+-_r%5)`H9vtBl~;
zuLB3T_3@fAN2}Y7=(7#K%$X1V3iN!Ys(p-YaUdWyefZ329fmfX)V5-Nq5%22nOZX7
z^sVY9tEsKQ0t!Cr`^WtQEV#jChd@vb&$eds@UzR2*e0Ezw1k<-0KkVMa&(y^s_~+g
zi+#~i0cLkWTV6d79+x)&P?)OY?JoK5J-PoSoWD_ptF3a%2>0gNBFC_6x(sD?vfKr|
zWkI1zL1ZjW^?c#|@oEiZHu5$Ht%@5+Ior+`Jng&=S0hV-4ao`$P6}2)nDfr0F<|zB
zJkVmxFbbE0h{#ev9rT=oXa
zpAhtPnhGpkuHX*31z}CQ1wFv^BfRp`nLyZUN
zZmOrO=}P&^@65$@z4y7#yUt+qmtAvh@$CacQRXZ)>z_*VbTBh<=T5E_H>xP&Ud_e(
z=dT1jf#Ke|v3;cg>yFTwAmy|0O@vX}aZ%+g)-|1Vd&d@fGzR);V)d
zz7~O!z#Yx$n2a`S!aZ}p6P1{Z*vv#(g%#}KcaX0G!V-JDA#ex6YrL30SS}GK=s=OPP85Zfa+$*0
zUD<1KRIlL>2uSo-Y7JL+QD$*02=0f80f|
zew3)sWt8gS;DIMywnCzRW1}cFY)s{{FWxL>V9|ahl$?6kx;*zky6}|~vgBbHlooKq
z#kL%ER;M(w7m%K~E%)b+-oP-$o8?IQN>bVuzbGJ9%)hj079uB{-EP~Fo!jC1LE}&L
zzl_s05nq|R-!f?)l|5lLHstx;`9Zt{SBX>NDx@Nk!F0*eqDWM(9SAW@&%
zVC~;x;?w4Si@Wa>GeDy4C8Xd$RnzhHr{A7E!&=>fE@nc*T6_8&$8gXnNFfUXn#(;tC2m%cD5(-f|>XF$mvap&xL
z9+WKUkc;^X9#t1msVMdy|2rQLWW%8d0YGN+om49-)GBIff*Soj1$=10Z~!pU$p%EI
zSqvL%gAdqQX;oEK8GWXSHvX=SWjB)_|Kx@p6(rg|Yk=;Rk3P$20`rDBfYdOuk+?Bf
zYz~s%gcoz3c3UStH`h(-QSp2>l%j`-i&$r$+npdTaN#iTNlFCZiLlEYpM2)B!NkQ7
z;7UUEYN>Yd)(5GsBK4nbs#d}ih*D2y{BypJO-G?4HK=C{DY>4jiQxG*xo9uW@+;#u
zChmXO*eejmmNs7MuMg)
zDm`_|HiBCkE2Jas=L)JJ*lJ>gpn+MM4^Fy1vTXiF&WiB4&P02l1a`@7o$t3TXvojT
z2D80tkxq>!i5Xa?A;X`s3zx^Sjb8vfpQUs^Qc3h19YERa
zH(u`tIbzee(IZw)M@zM%ZyRX6SBa8*5LYCQLhi>OlHkCRL>zg{9>LQ{_i`;NC^wfI
zU_M5!xuLffNyq5~k^}6pV;T7rp1UB@D17x!c$*{-K5O^3t=-Dby0Fz+0_TV@xXeI&
zfj!)kf@Efo3FwWCtC)AuK+HL2y(Hzuf&_0tudny&?3NJ*cF@8qFyYA)`DWANtQ35ArC_p!3~laBLoUGnf!|Q((p6bmDhd757<;
zT6`(O*778;`-KOoxGMrrl))gi(mQq=Zt3McwK3zN_qpNEHWOD%UhcNJGnttqbX2ThV39GwHIZi;ND@=4-8pWkzssSu=89M~Htf@EfY!f_?vU}f1rf0r(
zGBZtIcVz
zsnB)|cE#FyLZ6TcY=oaba&~1U-7%!gF8GOkZ%txn4cWqcc*xlb-=6|FhuxzHiU|t7
zm^Y=N(H@}@Yph-S&;={bw=f^@`VVD-L|>ja9CScw?ID#j9#+DDkp7R~+|!sB9VkDK
zvZhN(uZxV}?~2ksn0hE3-=pMnFOBfbX|A+uISoV&zSw_oi+#v`yCLw%07uBUE}r|y
z4&0&guXg~j2>dtrkhq$?N`bW~Ra7kRc5+@~_qoFLcI$ZzvW8tq9S2N&=x#}VgoezV
z!$va1mkDg%02&YG%2Zz5K`2tV@%r{)1(0AmP-h?TxM~Y$ZxVica5kym^%PLKfAn00
zV^jOK;fwqO08i1VB?gFDGQ>fOC+bI1N^+rG*L8o4>ix@a0(?=go!P|~Fhp-`Q%Du9
z6Cs%L1JUC1A8&9$1YBje!}I|A$$8h6!!~?$h>lYWCaR$7JgKiQOLm#X?u7=tPp}~d
zU?se$puj-e2RWdT4HPh6n$G#%2kHPi7joO1@!}H0Hmo`4i+M2Z){4D=^alOj=qOcf
zzZLHNr7L(bQro%|^L*BI@eLI?`afO{1u2R_J(t6ZYmGn51CL{~`B)kprDz0n^Wb2EKeRzcJ7KFj4c5}8+&IhZhatpL+
zcZv^l`N!4Y?4;_?hjXL`(D`>bO12WF#EMnd(xq&)%>E?n{z>HjT71xzYI~Nvt5U`N
zbXdBppRSjTd$?Na`;w_YdapMoA#dQ^u0v51+RLsKkazILh%Hc06~P_7P}W_XF&GWv
zw~!xk<;MLj-HyN}JV3UC?tUM!ny;9+_Nrw<3_mMYR9bZ>K<8^Ay3ayF4==
zYT%j@{H5HxciOkK>s(ZhbH_I9rPUWp8eJc6YR~RJaVbod8q;w+lUu?2oW}Tg?9D^6
z8Xg$@wDN}J+Ku1)W0J?_1(~SLjzd?c5h(16v3qgz2#}V`ehd_>T>|DD1aiQ
z4)+@RguUF*MeXN)b$n*xeb)L12xLFF<2k|z_wwJ4`n7La8ZA9=m!{f?@}{CYwz^n^5sexD@=4b
z6>(SSp!}iY?PV7#lXA0ER43~{1*AV3WOhVnxBO(FbWykQz<3}@&}};}2h#3C2Nv*3
z9hvSIR3hac6rN2JQp6VQOwNj80!WGJ-pt!+8neMpvjO3`pu5+xFacLapo93m9c
zRXhK-e7v^3Ot$)6DjG0cL&i?xSQH~_x87OwWCz`ZsXz}#Uuz(rIvX;|Zu5qpw4Xz0
z0l%|uYcy|6?O_M8)dXQ8$JkZ)@%y%ZpT$(y<@?keu3WSlbK&gzRg53^eQP2Ui?rE)
zoi^y9TrgrXQWsnfTQ2|hJOv_~%jDiaceXFf2>qt(`2$A(Dd1+O;(?^gNu>o&_5kvR
zhe~@msB`Z91;8UYi<_c`^@M!bO&2;obA!+2QozFthJp^w)GPU~J)@J80mh5hdVSX&
z>=5D+?gWZ)5IPqZy@h-~YhHu`XyWpP|Asp%&((s8ma+QY6sTQ*x@-Un&K>4mZPPfk
z?!I_#Y@f6%s~E6)`G9b=l}`|+uoKx#o8kh1qz-A(8$++N9sRED@d7l7P>wXhE9dhK
zsQxw-aG&8L*S{z^f9KLdPWeahCA~`-_yhzrJeoA4MTV7z_R>P`R6q%H??
zckIG4pG<)Jf-(`O%Yb?#*S5t2rjUo?A*sP3Ul{lvP_9Im_~g1U#4aPpaj~pFQnvqi
ztBS?bRHUDtAXTzw3RA^g?$d#{X5PNh#!Vd|KLud?
zqq@AXv2-BCszK^B@~3`6=QH?uO@gMkSNTFd1rx&)1i%gq!G&julC{CM$^
z%be>1`r6o6ro2HiyGN&A2^k|$34gRYrLZ`Cg6Ge69h{r@BOMmLaoe}=!!G-dz6QV-
zYnGyeYK@bdhM{qQb^N#e9Xg7x-jk$J|3T(MaWRT`opmuj(vWiViQsPz6v62YU!jve
zFVDxkumA<>eUCn>g+nYSSLcqDSwH}kJrHbITugP#IQ2#XquD4HRihoH1RfTn8Mf!y
zJ{Z2ha-!@Mp$*JeF1L_31i)sfqZ3=%Pl0b5;~(p;u&O4J2{&|KcXi#bO3Ch~J@?V?
zJ<)v@{S4;4wHAAHG^*J4t7=|NCAC;wc?H^0F%a834jSYJuYb~Q$vJ2lkZ{0-B_2Hbn{o2)Ts4TFKxzbi*
z!|&ij4yC=%31?b~0F!IOZ;d;U5D>$6C8vc|QHRkL1sk`+nq>c6+pLiN~o8JI6%$ED`{5rM-BC5yOh{oBIxH
zw2M;~lfo#Iy@&==7r?>4%h?4uaq3&K^MI2$^D&A%K>Gl|rH!GdiznM~xe5ziz0n9Y
zG9BbSTVXSo_Nm{-ki+F
zAY~7xyESWmCuw`-JUg2|ncLvsZ4|;6IvpCJHHFr%KDasjA;;l3Yva(2hW!^==DJ|`
z_MIk`Pr=D*`}fBMA4sC;gJcQI7@1A`YHPFKYfkdQa(5EcbtioV>6zo219Rg@lpl35
zaQ8tXRlDGbI6>Z={dX6qeW$A@o+;k7b=wQq3!VjL2HSg%1Av1Spu!|Qk=sLR)d*@C
z;3meikm|GGE^r=a{5>TFAJRQvMWF9>geiJ;stRegDsBo>q!B{Vx;fy7uwIkNxqIGv
zybm5m{_xEoRI#-!B8o5rW1!kG-JMG;1h}}kOaqu4RLM&r3a<$PZWZHoE-pIu{pO_U
zGR_mkbtt95uvAc59fC#`4Li*WBIaR|FF`Y8O)2IOl@E$LoDJYf|OjA+j7Jqj6LV?S~QT9R!D+^m)wr9JTFAN~}Q5
zcjLC3?EQi#4qmz4LS}=_Z^%l_8YdazE*kXOm-nN$3AM5mRuj`(tTT?3MJm#$54sfi
zoKKpal5_EASLpEH)8*z3&K|mt!mEiobqDO>B||xtYVi6rT^@M)x?((zMxxR6`Cc%&
z$*^AFSBnaly%|0Wf3#Bm_OVj!m(fU;{99MIt`FG9=hsw)RhKE=pd_20E={uc`-
zx(Vvy0UI3a1y#-ac|QD8FSEr4SwF42sKpyWtob$>Xo?~N#722ACiZ>zPujqUC3Pmg
zqZRJZ#sNT8whpC>b2@DfsU5`^!eL?-=ugyLpO=IqNL0d
z37qxd*NHtR@AKjHY7~pi<2|eJ?SSB&(T;3NgY5wRBvAtdz1Z-^t(yP?d!SjCU7yP2
z8R-#0on_G8Y!w0EI1#B9e#+&YnfXD1)h-IHe2-X)3DHvKr554Z)zDWG4@uOIVmvCk
z_#FyNrFl4}Ia+;Xx%-}dHG*wM7#26Epv%Z9@ai4R*O7tyJMOH@Mv-o(mF-8T?XkO>
znws5z{)oG~3ob7&XG~ncy#&BTK9o2F$m^CbM=Qe(+We26K4oHIxeI;?fO^k%N&Zyx
zj``j~gOHJS3KnPd9t%W(8Xw5>@oGTN23dX|gX!Znjaq98P#M5Vui<$Yb8#-m#KDo9{IJPq
zdK}bmLaS}K4;)Atz7csNak*+cQv6ynF5m$*deq5-r4@WMlr%-q>kDP=y=JJz?_YUs
zaE6aDvFqz-uhg#Zbti}}4mXjOK*0KyvNUrQ;l7M?v*V4yW(#4x{tbTrT48;ac2`XW
z$&1>}jENh~pVy~OgDLkJX?uQ3=|o634~}|rMf)anKD6sPlNpqSCLz(*gi{G7bNC`|
z$oezv1YjvN?37^TAhQ